Principes de l'analyse factorielle discriminante
Certains termes statistiques font penser à un régime politique inquiétant : loi normale, degrés de liberté, analyse discriminante… Cette dernière connaît pourtant des applications très pacifiques, notamment dans la recherche médicale.
Pénétrons dans ce monde mystérieux.

L'AFD
Imaginez une ACP qui, au lieu de résumer un nuage de points, cherche à séparer plusieurs sous-groupes préexistants, mutuellement exclusifs. Grosso modo, vous avez là le challenge à relever avec l’analyse factorielle discriminante (AFD).
Bien qu'étant une analyse factorielle, cette technique se présente donc comme une classification, mais supervisée puisque l’on « connaît la réponse », les observations étant déjà affectées à des groupes. Ce que l'on souhaite savoir, c’est si ceux-ci sont suffisamment distincts entre eux et quels critères permettent de les distinguer. Contrairement à l'analyse discriminante prédictive qui en constitue un prolongement, l'AFD est seulement descriptive.
On utilise donc cette technique pour expliquer les modalités d'une variable nominale par des variables numériques. Si la variable à expliquer est elle aussi quantitative, on emploie la régression multiple tandis que si ce sont les explicatives qui sont numériques et la variable à expliquer qui est qualitative, on a recours à l'ANOVA.
L'AFD permet de représenter graphiquement un ensemble d’unités statistiques par un nuage de points scindé en \(k\) sous-nuages déjà identifiés, par exemple des prospects qui se disent intéressés par un produit et d'autres qui ne le sont pas. Ces individus sont décrits par \(p\) variables numériques qu'il est pratique de standardiser (soustraire de la valeur observée la moyenne afin de centrer puis diviser l'écart obtenu par l'écart-type afin de réduire).
Les points représentatifs des individus sont projetés sur des axes factoriels orthogonaux entre eux, dans un espace vectoriel à \(p\) dimensions. Ces axes ne correspondent pas à telle ou telle variable observée mais à une combinaison linéaire de ces différentes variables.
Analyse discriminante à deux groupes
Si l’on ne veut séparer que deux classes, par exemple les clients bons payeurs et ceux qui connaissent des incidents de paiement, en fonction de deux variables, par exemple leur âge et leur ancienneté professionnelle, c’est une simple droite qui partage le nuage de points. Bien sûr, cette séparation ne sera pas parfaite et certains clients seront mal classés…
Attention, comme toute analyse factorielle qui se respecte, l’AFD va se traduire par une PROJECTION de points sur un axe gradué. Le but n'est donc pas de trouver un axe qui sépare directement les deux sous-nuages comme une frontière mais au contraire d'en déterminer un qui passe par les deux groupes, comme l'indique l'illustration ci-dessous (ce sont les coordonnées des projetés sur l'axe qui doivent être aussi distinctes que possible).

Comment trouver l’axe qui recevra d’un côté les projetés de la classe \(A\) et d’un autre ceux de la classe \(B\) ?
Deux possibilités sont offertes mais, sauf hasard extraordinaire, elles ne donnent pas les mêmes résultats : soit trouver l’axe sur lequel les barycentres de chaque classe auront les projections les plus éloignées possibles, soit déterminer l’axe sur lequel les projections des observations intra-classes seront les plus rapprochées. En fait, c'est une combinaison de ces deux possibilités qui sera réalisée.
Plusieurs métriques sont envisageables mais si l’on s’en tient à l’euclidienne, l'exercice revient à maximiser l’inertie interclasse projetée sur l’axe tout en minimisant l’inertie intra-classe projetée. L’idée est alors de maximiser le rapport de la première sur la seconde, ce qui est un excellent compromis… Mais attention, avec ce tour de passe-passe, la métrique n'est plus euclidienne.
Notons que la ruse qui consiste à découper une variance (ou une inertie si les observations sont de pondérations différentes) entre intra-classe et interclasse est une technique largement employée : ANOVA, k-means…
Donc, le nuage global est centré sur son barycentre par lequel passe notre axe. On démontre que l’axe qui sépare le mieux les deux groupes, également nommé droite de Fisher, correspond au vecteur propre associé à la valeur propre de \(W^{-1}B.\) La matrice \(W\) (Within) s’interprète comme une moyenne pondérée des matrices de variances-covariances intra-classe tandis que \(B\) est la matrice interclasse (Between) qui synthétise les distances entre barycentres. Nous avons vu que la métrique employée n'est pas euclidienne : c'est celle de Mahalanobis (inverse de la matrice des variances-covariances intra-classes). Il existe une variante à la méthode qui consiste à utiliser la matrice des variances-covariances GLOBALE au lieu de \(W.\) Les vecteurs propres restent les mêmes mais les valeurs propres diffèrent.
Les coordonnées des observations sur cet axe représentent la variable canonique.
Pour bien voir que la métrique à utiliser doit tenir compte non seulement des centres de gravité mais aussi de l'inertie de chaque sous-nuage, il est pratique de se situer dans le cadre de l'analyse factorielle prédictive. Ainsi, dans le graphique ci-dessous, le point représenté par un triangle vert est indiscutablement plus proche du barycentre du nuage rouge que de celui du nuage bleu. Pourtant, il est assez intuitif que sous son déguisement se cache plus sûrement un point bleu qu'un point rouge.
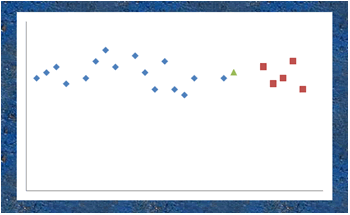
Note : il s'agit d'un exemple caricatural pour lequel les hypothèses de l'AFD ne sont certainement pas vérifiées.
L’algorithme de l’AFD est donc un peu plus complexe que celui de l’ACP en raison de sa métrique particulière. Mais si l’on excepte ce détail, l’AFD est tout simplement une ACP sur les centres de gravité…
Analyse discriminante multiple
Si \(k\) classes sont à séparer, des axes canoniques, orthogonaux entre eux, généreront un espace factoriel de dimension \(k - 1.\) Le principe est le même que pour toute analyse factorielle (axes triés en ordre décroissant de leur capacité à expliquer les différences, étant entendu que ces axes représentent tous des critères abstraits, combinaisons linéaires des variables observées).
Plus la première valeur propre est proche de 1, meilleure est l’AFD. Si elle est voisine de 0, l’analyse ne discrimine pas grand-chose.
Pour que toute cette mécanique fonctionne correctement, il vaut mieux que les variables soient distribuées normalement dans chaque classe, quoique l’AFD reste relativement robuste si cette hypothèse n’est pas très bien vérifiée (comme disait F. Dard, « c’est moins grave que si c’était pire »). En revanche, les matrices de variances-covariances des différents groupes doivent être sensiblement égales. Nous vous renvoyons à la page sélection de variables discriminantes pour plus de précisions. Si ces variables montrent une fâcheuse tendance à l’hétéroscédasticité, on se tourne vers une AFD quadratique.
La plus ou moins bonne validité d'une AFD se mesure avec le lambda de Wilks.
Une illustration pratique ? Rendez-vous en page exemple d'une AFD descriptive.
