Généralités sur les analyses en axes principaux
L’art de lire dans le marc de café s’appelle la cafédomancie ; l’art de lire dans le plan factoriel s’appelle le data mining. En quoi cela consiste-t-il ?
Analyses factorielles
Avec les classifications, les analyses factorielles (ou en axes principaux) sont des techniques d'analyse de données qui s’accommodent sans problème de milliers voire de millions d’observations. Tels des orpailleurs devant brasser des tonnes de terre pour trouver LA pépite, les data miners vont utiliser ces techniques pour tamiser les données et extraire la super info… Précisons tout de même que ces techniques ne sont pour la plupart que descriptives. C'est à l'homme de métier de trouver l'explication des liaisons.
Le point de départ d'une analyse de données se présente toujours de la même façon : un tableau d'observations. Celui-ci comporte autant de lignes qu'il y a d'individus (ou unités statistiques, il ne s'agit pas toujours de personnes). En colonnes figurent les valeurs des variables aléatoires prises par ces unités statistiques. Les variables sont souvent quantitatives, auquel cas le tableau comprend autant de colonnes qu'il existe de variables observées. C'est un peu plus compliqué lorsque les critères sont qualitatifs.
Les analyses factorielles permettent de détecter des proximités entre variables, entre individus et entre variables × individus, mettant à jour des liens ou au contraire des « répulsions ». Pour une analyse de marché, par exemple, elles assurent l’identification des segments de clientèle à partir de variables mesurées (code PCS, types de commerce habituellement utilisés, revenu, catégorie de logement…). Le segment apparaît alors comme une dimension supplémentaire, cachée au départ mais qui sera le critère grâce auquel le produit pourra être positionné. Les analyses factorielles conduisent aussi à identifier facilement des valeurs aberrantes, qu'il est alors possible d'éliminer pour reconduire l'analyse. Enfin, elles permettent de hiérarchiser l'importance de critères éventuellement explicatifs.
L'analyse des données apparaît donc comme une forme TRÈS élaborée de la statistique descriptive. Comme l'écrit Ludovic Lebart dans l'introduction de l'un des manuels qui font autorité en la matière, « le passage au multidimensionnel induit un changement qualitatif important. On ne dit pas en effet que des microscopes ou des appareils radiographiques sont des instruments de description, mais bien des instruments d'observation ou d'exploration, et aussi des outils de recherche », in Statistique exploratoire multidimensionnelle, L. Lebart, M. Piron, A. Morineau, Dunod 2006. Si certaines techniques permettent l'exploration, d'autres impliquent la confirmation d'une régle préétablie (analyse discriminante décisionnelle).
Derrière tout ça, il y a bien sûr des mathématiques et en particulier de l'algèbre linéaire... Le passage aux maths s'effectue dès qu'un tableau est considéré comme une matrice. Visuellement, les \(k\) variables peuvent être représentés par un nuage de points dans un espace vectoriel de dimension \(n\) et réciproquement, les individus prennent la forme de points dans l'espace des variables. Bien sûr, au-delà de trois dimensions, une représentation graphique unique devient impossible et il faut ruser. L'intérêt de l'opération est de visualiser des proximités. Supposons qu'une enquête a été conduite dans une entreprise. On s'intéresse à l'espace des salariés. Parmi les points représentatif des variables, on s'aperçoit que le point « âge » est très proche du point « ancienneté ». Donc, l'entreprise recrute à peu près toujours au même âge et il ne servait à rien de demander aux salariés leur âge et leur ancienneté.
Les unités statistiques, comme les variables, se situent dans le même espace qu’avant (endomorphisme) mais on connaît leurs coordonnées sur de nouveaux axes, orthogonaux entre eux et triés selon leur capacité à maximiser l’inertie qui est projetée sur eux. Pour dire les choses moins techniquement, l’analyse factorielle permet de mettre en évidence une grandeur synthétique abstraite qui différencie au mieux les individus (ou les variables) entre eux, puis ce qui les différencie dans une moindre mesure et ainsi de suite par ordre décroissant d’importance. À ces grandeurs il est plus ou moins facile d'associer une notion. Graphiquement, la proximité de deux points-individus dans l’espace des variables ou de deux points-variables dans l’espace des individus signifie qu’il existe bien une proximité statistique au regard des critères étudiés. Surtout, ces grandeurs abstraites sont totalement indépendantes les unes des autres.
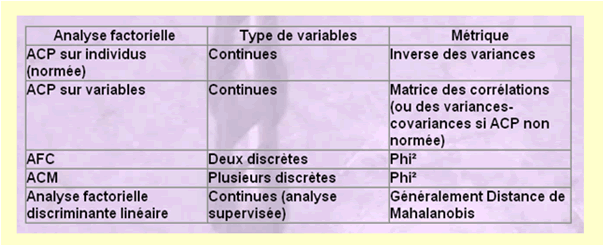
Comment réussir un tel prodige ? Nous vous renvoyons aux différentes méthodes énoncées en bas de page. Tenons-nous ici aux généralités. Pour chaque type d’analyse, une métrique est définie pour mesurer la distance des points entre eux et par rapport à un axe. Les métriques diffèrent selon le type de variable analysée (quantitative ou qualitative) et sont également indiquées dans le tableau ci-dessous.
Contrairement aux dimensions initiales, les nouvelles dimensions sont par construction totalement décorrélées entre elles. Elles sont des combinaisons linéaires des caractères d’origine et leurs équations font donc intervenir des facteurs \(a_i.\)
Attention, on ne confond pas une analyse factorielle avec une régression multiple ! Il n’y a ni variables explicatives ni variable à expliquer… Même régime pour tous !
Interprétation des axes
Soit le responsable d’une bibliothèque qui cherche à déterminer le profil des lecteurs. Qu'ils le veuillent ou non, ceux-ci prendront la forme peu enviable de vecteurs dans un espace à \(k\) dimensions. Admettons que, parmi la dimension « sujet de l’ouvrage », on retienne (entre autres) les quatre modalités jardinage, bricolage, sport et guides de voyage. S’il existe une séparation plus ou moins nette des lecteurs entre les deux premières catégories et les deux autres, la réduction de dimensionnalité se traduit par un seul axe sur lequel (ou autour duquel, dans un plan factoriel) se situent d’un côté les jardiniers et les bricoleurs et de l’autre côté les sportifs et les voyageurs. L’interprétation de cet axe factoriel est assez facile : on peut l’appeler « type de loisir » et il sépare les lecteurs dont les loisirs se passent essentiellement à domicile de ceux dont les loisirs sont plus extérieurs. Bien sûr, cet axe ne sera pas extraordinairement discriminant si de nombreux lecteurs s’adonnent à différents types de loisirs…
La force des axes factoriels est donc que non seulement ils détectent les critères qualitatifs pouvant expliquer une diversité, mais ils les quantifient. En un mot, ils font la part des choses (voir les sorties de logiciels sur une AFC).
Les analyses factorielles sont souvent associées à d’autres techniques statistiques ou d'analyses de données, en particulier les classifications (voir ACM) et la régression multiple (dont les variables explicatives peuvent être des coordonnées sur des axes factoriels).
Dans les entreprises d'une certaine taille, la direction du marketing s'appuie sur des cartes conceptuelles issues d'analyses factorielles pour cibler une clientèle et positionner leurs produits.
En page de statistiques sur les effectifs, vous trouverez des exemples d'analyses factorielles adaptées à la problématique des départs de salariés.

Différentes analyses factorielles
Les plus courantes sont l'analyse en composantes principales (ACP) sur les individus, l'ACP sur les variables, l'analyse factorielle des correspondances (AFC), l'analyse en composantes multiples (ACM), l'analyse factorielle discriminante linéaire...