Axes principaux et réduction de dimensionnalité
Les analyses factorielles, ou analyses en axes principaux, comptent parmi les outils statistiques les plus puissants et les plus utilisés. Certes, on peut les réaliser grâce aux logiciels d’analyse de données sans se poser de questions mathématiques. Mais on peut aussi chercher à comprendre d’où sortent ces fameux axes et se dire ainsi qu’on n’a pas étudié les produits scalaires et les opérations sur matrices pour rien durant ses études secondaires et supérieures...
Régression vs analyse factorielle
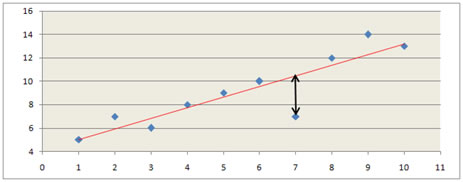
En préambule, un petit rappel sur l’aspect « visuel » de la régression linéaire simple (RLS). On cherche à résumer un nuage de points représentatif d’observations par une fonction affine qui se traduit par une « droite des moindres carrés ». Pour calculer l’équation de celle-ci, on minimise la somme des carrés des distances entre les points et cette droite. Les distances sont mesurées parallèlement à l’axe des ordonnées.
Entrons maintenant dans le domaine de l’analyse de données tout en nous situant à un niveau général, les spécificités propres à telle ou telle technique étant indiquées sur les pages de ce site web qui les présentent.
Les analyses factorielles sont conduites à partir de tableaux de données parfois gigantesques : si l’on observe cent mille individus caractérisés par trente variables, on place les points-individus, qui sont autant de vecteurs, dans un espace d’au plus trente dimensions. Si au contraire on cherche à placer des points représentatifs de variables dans l’espace des individus, celui-ci est composé d’au plus cent mille dimensions !
La réduction de dimensionnalité
Un des buts de l’opération est de ne conserver que des données utiles au problème à résoudre. Ceci suppose en amont un nettoyage des données : élimination de valeurs aberrantes, de variables trop bien corrélées avec d'autres, etc.
Graphiquement, une analyse factorielle permet d'obtenir un nuage de points d'une forme proche du nuage initial mais dans un repère modifié. Si l’on change la base de l’espace dans lequel se situent les individus ou les variables, il est généralement possible de diminuer drastiquement le nombre de dimensions, donc d’axes. Par exemple, on peut disposer de vingt critères de départ pour qualifier des unités statistiques mais, pour les décrire, on ne se servira que de deux ou trois critères « fabriqués » pour l’occasion tout en perdant peu d’information. Attention, le même nombre d'axes existant au départ est conservé. Les axes factoriels sont juste triés en ordre décroissant de significativité et c'est l'analyste qui choisit de n'en retenir qu'un certain nombre. Une partie de l'information est volontairement perdue.
Le but est double : expliquer les phénomènes analysés de façon plus synthétique et obtenir des modèles robustes.

Le premier axe principal
À l'instar de la RLS, les analyses factorielles visent à résumer des nuages de points par des droites. Toutefois, l’objectif n’est pas de montrer qu’une variable est susceptible d’en expliquer une autre. On cherche juste des proximités. Du coup, la façon d’évaluer les distances est un peu différente. Ce qui est mesuré, ce sont les carrés des distances orthogonalement à l’axe qui synthétise au mieux le nuage. La métrique dépend de la technique d’analyse (ACP sur individus, AFC...) mais ceci ne sera pas approfondi ici (voir le tableau de la page analyses factorielles).
Contrairement à la RLS, la droite ainsi déterminée est elle-même un axe.
Le premier axe est celui qui doit résumer au mieux la forme multidimensionnelle du nuage. Il s’agit d’un sous-espace vectoriel à une seule dimension sur lequel tous les points sont projetés, généré par un vecteur directeur \(u\) qui passe par l’origine et dont on va chercher les coordonnées.
La direction de \(u\) : c’est ici qu’intervient la notion de produit scalaire. La distance entre l’origine \(O\) et le projeté \(P\) d’un point \(A\) est égale au produit scalaire entre \(u\) et \(OA.\) Rappelons au passage que, dans un espace à \(p\) dimensions, un vecteur est représenté par une matrice colonne de \(p\) lignes et qu’un produit scalaire s’obtient alors en multipliant deux matrices, l’une étant la transposée d’un vecteur (donc une matrice ligne de \(p\) colonnes), l’autre étant le second vecteur présenté sous forme de matrice colonne. Le résultat obtenu est évidemment un réel.
Au fait, quelle est la longueur du vecteur directeur ? Celui-ci doit bien sûr être unitaire puisqu’il sert de norme. Donc le produit de sa transposée par sa matrice colonne doit être égal à 1 (Cf. règle du produit scalaire ci-dessus).
Puis on retrouve ce bon vieux principe de la régression linéaire, à savoir minimiser les carrés des distances. Pourquoi les carrés ? Parce qu’entre l’origine, chaque point et son projeté, il existe autant de triangles rectangles. Or, on sait depuis Pythagore que le carré de l’hypoténuse est égal à la somme des carrés des deux autres côtés. Et que s’il y a \(n\) points donc \(n\) triangles rectangles, la somme de toutes les hypoténuses, etc. (vous avez compris). Donc :
\[\sum\limits_{i = 1}^n {OA_i^2 = \sum\limits_{i = 1}^n {OP_i^2 + \sum\limits_{i = 1}^n {{A_i}P_i^2} } } \]
C’est évidemment le dernier terme qu'il faut minimiser. Ce qui revient à maximiser \(OP^2\) puisque la distance entre \(0\) et \(A\) est une donnée. Cette maximisation conduit à chercher là où le nuage est le plus allongé pour que l’axe lui serve de « colonne vertébrale ». On recherche l’inertie maximale du nuage par rapport à l’origine.
Présentons cette somme de carrés scalaires sous forme matricielle. Soit \(M\) la matrice du tableau de données. La matrice représentative de toutes les distances entre l’origine et les projetés s’obtient en multipliant \(M\) par \(u.\) C’est du produit scalaire à l’échelle industrielle. Donc l’inertie de la projection du nuage est égale à :
\(\displaystyle{\sum\limits_{i = 1}^n {OP_i^2 = (uM)'Mu}} \)
Admettons sans démonstration que la maximisation de cette somme sous la contrainte \(u’u = 1\) implique que \(u\) est le vecteur propre de la plus grande valeur propre de \(M’M.\)
Implicitement, nous avons supposé pour simplifier que tous les points étaient identiquement pondérés. Évidemment, cette situation n’est pas toujours vérifiée et les pondérations sont bien sûr, à introduire dans les calculs de distances.
Les axes suivants
Les chances de résumer correctement un nuage multidimensionnel avec une seule droite sont minces ! La recherche des axes suivants ne nécessite aucune opération supplémentaire puisqu’à la deuxième valeur propre de \(M’M\) est associé le deuxième vecteur propre, orthogonal au premier, et ainsi de suite. Par construction, tous les axes sont orthogonaux entre eux.
Le deuxième axe est, comme le premier, un sous-espace vectoriel. La somme directe de ces deux sous-espaces forme le premier plan factoriel. Et ainsi de suite avec les vecteurs propres suivants.
Sauf si les deux premiers axes suffisent pour expliquer la quasi-totalité de l’inertie, il faut plusieurs plans repérés pour donner un bon aperçu du nuage de points. Un premier plan factoriel pourra avoir pour abscisses les coordonnées des points sur l’axe n°1 et pour ordonnées celles des points sur l’axe n°2, un deuxième repère utilisant les axes 1 et 3, un éventuel troisième plan situe les points sur les axes 2 et 3… Il est rare d’aller plus loin.
