Robustesse en statistiques
Dans le domaine des statistiques inférentielles, la robustesse est un concept récurrent. L’objet de cette page n’est pas d’expliquer comment faire subir des crash-tests à nos pauvres statistiques (bien que les banques soient astreintes au stress testing de leurs modèles de risque). Plus modestement, nous nous contenterons d’énoncer quelques principes de bon sens, à appliquer avant de se lancer tête baissée dans une étude.
La robustesse est la capacité à généraliser les conclusions d'une analyse statistique. Cette notion va au-delà de celle de validité d'un résultat (les statistiques descriptives exigent des résultats valides mais la question de robustesse ne se pose pas).
Quelques robustesses…
Un test est robuste s’il reste valable alors que les hypothèses d’application ne sont pas toutes réunies. Ce peut être une taille d'échantillon un peu faible ou l'adéquation à une loi de probabilité (loi normale pour les tests paramétriques) qui n'est pas très bien vérifiée.
Un indicateur est robuste s’il est peu sensible à la présence d’outliers. Le coefficient de corrélation, par exemple, n’est pas très robuste.
Plus généralement, un modèle est robuste lorsqu’il permet un prolongement des résultats (dans le temps ou pour une population). La robustesse s’applique aussi bien à une régression multiple qu’à une grille de score. L’emploi du terme « modèle » est d’ailleurs restrictif : les cogitations d’un réseau de neurones (qu'on ne peut pas considérer comme un modèle) sont elles aussi plus ou moins robustes.
Par conséquent, à moins d’être uniquement descriptives, vos études devront respecter quelques règles pour que leurs conclusions soient généralisables.
Les données
Première condition d’une bonne robustesse, les données. Intuitivement, chacun sait qu’on ne transforme pas un cas en généralité (ce qui ne relèverait pas des statistiques mais des discussions de comptoir). Il faut une quantité suffisante de données pour bâtir des modèles fiables et solides. A titre d’exemple, des prévisions établies à partir d’une série chronologique montrant une saisonnalité mensuelle nécessitent au moins trois ou quatre ans d’historique. Quant aux techniques d'intelligence artificielle, elles s'appuient sur le big data, c'est-à-dire des quantités de données pouvant être colossales.
La quantité ne suffit pas, il faut la qualité. Mieux vaut s’abstenir que réaliser une étude sur des informations non fiables qui peuvent conduire à des décisions coûteuses. Par ailleurs, il convient d’éliminer ou d’imputer certaines observations (voir les outliers). Si ce n’est pas possible, on se tourne vers des méthodes adaptées, par exemple celles qui utilisent la médiane plutôt que la moyenne.
Les statistiques sont une forme... d'artisanat : avec des outils et du savoir-faire, l'artisan transforme complètement un matériau. Prenons l'exemple d'un ébéniste : si la matière première ne présente pas une qualité suffisante (bois abîmé...), le meuble présentera des défauts. De même un data analyst qui ne dispose pas de données fiables produira des informations trop imprécises ou carrément fausses, même s'il dispose des meilleurs outils logiciels. Donc, la question à se poser est : « peut-on tirer quelque chose de ceci pour réaliser un travail de qualité ? »
La collecte et le traitement des données s'inscrivent donc dans une exigence de fidélité, c'est-à-dire d'objectivité, de recherche de justesse des informations, du codage le plus pertinent, etc.
Cette fidélité échappe en partie au data analyst. Supposons que, pour réaliser une étude de marché, des répondants goûtent un produit afin d'en évaluer les caractéristiques. Certains d'entre eux sont peut-être trop fatigués pour se concentrer sur le produit, d'autres ont la tête ailleurs... Bref, un test suffisamment robuste devra pallier diverses entorses souvent involontaires à la fidélité. Cette robustesse peut passer par plusieurs échantillons choisis dans des lieux et à des moments différents, et par une taille d'échantillon globale suffisamment importante pour que, théoriquement, des erreurs de mesure dans un sens se compensent par d'autres erreurs dans l'autre sens.

Le traitement statistique
L’amie de la robustesse est la concision. À vouloir intégrer trop de variables, à faire tourner trop longtemps un réseau de neurones ou à retenir trop de clusters d'une classification, on perd en robustesse.
N’oublions pas un autre critère, à savoir le choix de l’architecture du modèle. Trop sophistiqué, il conduit au surparamétrage. A titre d’exemple, une régression polynomiale qui cherchera à trop bien représenter la réalité utilisera un degré de polynôme trop élevé.
Explication. Un des aspects de la robustesse est connu sous le nom de « compromis biais-variance ». Si le nombre de paramètres est trop faible, le modèle est « biaisé » (régression simple quand on dispose d’informations utiles à une régression multiple, par exemple) et on se trouve dans une situation de sous-paramétrage. Mais à l’inverse, dans la mesure où les paramètres sont des variables aléatoires sensibles à l’échantillonnage, l’accroissement de leur nombre entraîne mécaniquement une augmentation de la variance, donc de l'incertitude.
Outre le nombre de paramètres, il faut bien voir qu'un modèle trop sophistiqué risque de ne pas tenir la route très longtemps. Sur les données ci-dessous accompagnées de leur représentation graphique (en bleu), quel modèle a-t-il le plus de chances d’être robuste ? La régression linéaire avec son malheureux \(R^2\) à 0,6 (en rouge) ou la régression polynomiale de degré 3 (en vert) avec son \(R^2\) de 0,8 ?
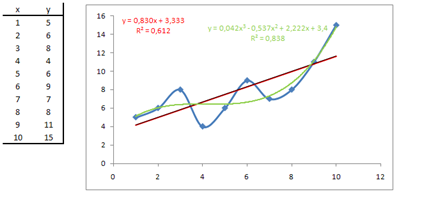
Certains outils permettent de déterminer un optimum (\(R^2\) ajusté). Souvent, les algorithmes des logiciels ou tout simplement vos yeux et votre bon sens vous aident à faire le bon choix (niveau de coupure d’une CAH...).
Sur ce site, les conditions de robustesse sont données pour chaque technique lorsqu’elles ont des raisons de l’être.
