Exemple d'analyse discriminante à deux groupes
« Quand il n'y a rien, il n'y a rien. C'est net. Mais quand il y a quelque chose, ce quelque chose cache souvent autre chose... (Michel Audiard, le Cri du cormoran le soir au-dessus des jonques) ».
Or, l'analyse des données est un ensemble de techniques grâce auxquelles on peut trouver ce qui se cache derrière les chiffres... Voyons l'exemple de l'une de ces techniques.
Problématique
Les données démographiques d'une population permettent-elles de différencier les clients des hypermarchés de ceux du hard discount ? Les styles de vie des consommateurs fidèles à tel produit sont-ils les mêmes que ceux des clients qui ne le sont pas ? Les caractéristiques d'un véhicule acheté à crédit permettent-elles de deviner si ce crédit est risqué ?
Le marketing et le crédit constituent deux domaines où l'on s'adonne à une consommation invétérée de l'analyse factorielle discriminante...
Voici une petite illustration théorique de cette technique. Nous vous ferons grâce de l’éternel exemple sur les iris de Fisher, habituellement repris dans la plupart des livres et des tutoriels.
Exemple
Dans le cadre d’une étude de marché pour un constructeur automobile, un échantillon de trente automobilistes est interrogé. Celui-ci est séparé en deux groupes égaux : ceux qui comptent changer de véhicule dans les deux ans à venir et ceux qui n'ont aucune intention de le faire. Possédant un type de voiture spécifique, ils ne sont pas représentatifs de la population (précisons-le pour que les chiffres n’étonnent personne).
On pose aux répondants des questions personnelles (âge et nombre de personnes dans le foyer) et des questions liées à leur automobile : nombre de km par an, âge du véhicule et budget annuel hors carburant (garagiste, accessoires, assurance...).
Note : la méthode pas à pas n’est pas utilisée dans cet exemple pour sélectionner les variables les plus discriminantes.
Variable à expliquer : 1 = pas de changement prévu. 2 = changement prévu.
| km/an | Âge | Taille foyer | Budget | Âge voiture | Change-ment ? |
| 3 000 | 50 | 2 | 4 00 | 5 | 1 |
| 7 000 | 37 | 1 | 1 000 | 3 | 1 |
| 8 000 | 28 | 4 | 1 200 | 3 | 1 |
| 10 000 | 40 | 3 | 2 000 | 2 | 1 |
| 13 000 | 70 | 2 | 3 100 | 1 | 1 |
| 15 000 | 46 | 5 | 3 000 | 2 | 1 |
| 20 000 | 31 | 4 | 2 500 | 3 | 1 |
| 20 000 | 47 | 3 | 2 800 | 2 | 1 |
| 25 000 | 37 | 2 | 2 500 | 1 | 1 |
| 25 000 | 32 | 2 | 3 500 | 2 | 1 |
| 28 000 | 52 | 3 | 3 000 | 1 | 1 |
| 30 000 | 39 | 3 | 4 000 | 4 | 1 |
| 40 000 | 54 | 2 | 2 500 | 3 | 1 |
| 45 000 | 62 | 1 | 2 800 | 2 | 1 |
| 50 000 | 35 | 2 | 2 500 | 2 | 1 |
| 12 000 | 29 | 2 | 2 000 | 4 | 2 |
| 15 000 | 30 | 1 | 3 000 | 5 | 2 |
| 25 000 | 55 | 2 | 3 000 | 3 | 2 |
| 26 000 | 55 | 2 | 3 200 | 5 | 2 |
| 30 000 | 40 | 5 | 2 500 | 1 | 2 |
| 30 000 | 47 | 3 | 1 000 | 2 | 2 |
| 35 000 | 36 | 3 | 3 000 | 5 | 2 |
| 35 000 | 59 | 2 | 4 500 | 7 | 2 |
| 40 000 | 35 | 3 | 3 000 | 6 | 2 |
| 42 000 | 36 | 3 | 3 200 | 7 | 2 |
| 45 000 | 42 | 4 | 2 800 | 4 | 2 |
| 50 000 | 44 | 4 | 3 600 | 4 | 2 |
| 60 000 | 46 | 2 | 2 400 | 3 | 2 |
| 60 000 | 50 | 3 | 4 000 | 4 | 2 |
| 80 000 | 51 | 2 | 5 000 | 4 | 2 |
Les dix distributions ont été testées et ne sont pas incompatibles avec l’hypothèse de normalité (voir l'exemple de la variable km / an en page exemple de sélection de variables discriminantes).
En utilisant XLSTAT, les tableaux de résultats sont nombreux. Sélection :
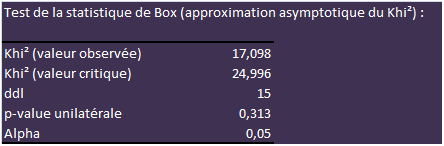
On considère qu’il y a homoscédasticité entre les matrices de variances-covariances intra-classes. À ce niveau de l'étude, on admet qu'il est légitime de procéder à une AFD.
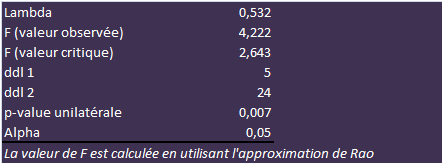
Le lambda de Wilks n’est pas trop élevé et sa p-value est bien inférieure à 0,05. Les barycentres des deux groupes sont suffisamment éloignés pour que notre AFD signifie bien quelque chose…

La valeur propre est assez proche de 1, signifiant que la discrimination est nette. Ceci ne signifie pas qu’elle est SUFFISANTE en soi puisqu’on ignore dans cet exemple le COÛT des mauvais classements. Et maintenant, ladies and gentlemen, le clou du spectacle :
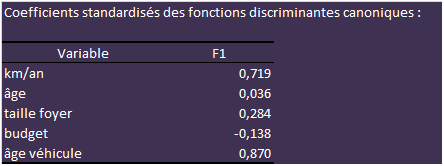
Les coefficients ci-dessus sont utilisés si les variables sont centrées et réduites. Sinon, on prend ceux-ci :
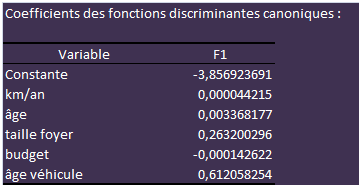
Si par exemple on applique ces coefficients au premier individu de la liste, on obtient une valeur de -0,026. C'est un nombre négatif, ce qui signifie que l'AFD classe cet individu parmi ceux qui ne changeront pas de véhicule (classement correct, en l'occurrence).
En fait, le nombre de km annuels et l’âge du véhicule suffisent presque à eux seuls pour tracer l’axe qui sépare au mieux les deux classes. La prise en compte de l’âge du propriétaire ne sert à rien. Voici l'axe :
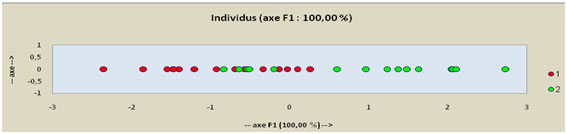
C’est donc surtout « l’amortissement » de ce type de voiture (en km et en âge) qui préside à son remplacement.
Pour information, XLSTAT restitue d'autres tableaux dont deux figurent en page matrice de confusion.
