Introduction à la régression linéaire simple
Le terme, au demeurant stupide, de « régression » est bien connu. Soit une distribution à deux variables quantitatives. La RLS (Régression Linéaire Simple) permet de montrer l'éventuelle relation fonctionnelle linéaire qui existerait entre une variable explicative (ou indépendante) \(x\) et une variable aléatoire ou une variable statistique à expliquer (ou dépendante) \(y.\) Dans le système de notation retenu sur ce site web, \(x\) est remplacé par \(t\) lorsqu’il s’agit d’une mesure du temps.
Exemple
Par exemple, on peut observer chaque année une population de tortues dans une réserve naturelle. La variable explicative est le temps (\(t\)) et la variable à expliquer est le nombre de tortues (\(y\)).

Graphiquement, on représente cette éventuelle relation dans un plan muni d'un repère orthogonal. Les valeurs de la variable explicative figurent sur l'axe des abscisses et celles de la variable à expliquer sont représentées sur l'axe des ordonnées. L'ensemble des données apparaît sous la forme d'un nuage de points (autant de points que d''individus, sauf s'il existe des observations strictement identiques). Au cas où les données ne seraient disponibles qu'en classes de valeurs, on utilise les valeurs centrales des classes (voir la page sur les séries de variables continues à l'attention des élèves de seconde).
Pour reprendre notre exemple, on note dans un tableau le nombre de tortues à chaque date annuelle de relevé puis on visualise graphiquement si la population croît ou décroît et s'il existe de fortes variations d'une année sur l'autre. Remarquez que pour cet exemple, on pourrait tout à fait tracer une courbe plutôt qu'un nuage de points...
Si le but de l'opération est de prévoir le nombre de tortues dans les années à venir, il faut prolonger le nuage de points. Mission hélas impossible.
En revanche, il est tout à fait possible de prolonger une droite d'ajustement passant au milieu du nuage de points.
Ainsi, une relation entre les deux variables peut être modélisée par une équation de droite. En mathématiques, on dit que la droite qui les relie représente une fonction affine (en statistiques, on emploie abusivement le terme LINÉAIRE plutôt qu'AFFINE).
Évidemment, on ne trouve jamais de relation parfaite en utilisant des données brutes, sauf à vérifier une définition (auquel cas on parle de modèle déterministe et les points du nuage sont parfaitement alignés). La relation est donc stochastique, c'est-à-dire qu'elle comporte une part d'aléas. Mais nous n'aborderons pas sur cette page le modèle linéaire stochastique. Nous en resterons à un niveau d'initiation à la régression linéaire.
Notez d'ailleurs que la relation entre les séries statistiques n'est pas toujours fonctionnelle. Si l'on cherchait à mettre en relation le poids de tortues selon leur taille, on pourrait tout à fait mesurer deux tortues de même taille mais de poids différents.
La RLS vise à modéliser cette relation par une équation de droite.
Petites mises en garde d’usage
Attention, même une parfaite relation fonctionnelle ne signifie pas causalité. Si les ventes de crèmes glacées sont corrélées aux ventes de ventilateurs, il n’y a pas de lien direct entre ces deux évolutions mais avec un troisième phénomène qui est la chaleur (une analyse de corrélation partielle consiste à vérifier si ce genre de liaison existe).

Par ailleurs, la RLS est particulièrement sensible aux valeurs aberrantes, surtout si elle est effectuée sur un petit nombre d’individus. Lorsque de telles curiosités risquent de fausser l'étude, il vaut mieux les exclure ou les imputer, voire opter pour une autre méthode que la RLS.
Enfin, il faut au moins une douzaine d’observations pour tirer des conclusions d’une régression, en particulier lorsqu’on s’intéresse à des comportements humains ou à des variations d’ordre économique. Hélas, il est courant de se satisfaire de moins, avec le risque de se doter d'un outil assez peu prédictif.
La droite de régression
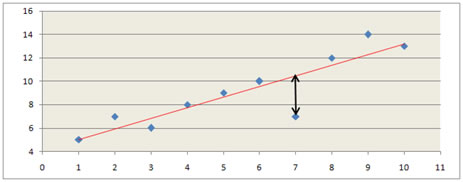
Bref. Nous observons graphiquement un nuage de points représentant les observations. Celui-ci est de forme plus ou moins rectiligne. Comment trouver l'équation de la droite qui le résume au mieux ? Théoriquement, il faut minimiser les distances qui la séparent des points. Lesquelles ? Généralement les carrés des distances euclidiennes parce que l’utilisation des valeurs absolues nous bloquerait dans une impasse mathématique un peu longue à expliquer (mais certains logiciels permettent de réaliser ce type de régression). D'où l'expression droite des moindres carrés. Graphiquement, il s’agit des distances verticales, donc parallèles à l’axe \(y.\) Ci-dessous, la flèche noire indique, pour l'observation n° 7, la distance entre le modèle théorique (droite rouge) et la réalité (point bleu).
Et pourquoi pas des distances horizontales ou perpendiculaires ?
Les droites que ces distances permettraient de tracer résumeraient également le nuage mais les distances horizontales impliqueraient une explication de \(x\) en fonction de \(y\) et les distances mesurées orthogonalement supposeraient une symétrie, comme dans le cadre de l’ACP. Cela dit, les trois droites possibles se croisent au centre de gravité du nuage de points (coordonnées : moyenne des abscisses et moyenne des ordonnées).
Les logiciels d'analyse statistique, tableurs compris, calculent l’équation de cette fameuse droite d’ajustement (\(y = ax + b)\), appelée droite de régression empirique, droite des moindres carrés (les termes sont synonymes dans le cas de la RLS) ou tendance si les abscisses représentent des dates ou des périodes. Les formules des deux paramètres font partie de la culture de tout data analyst :
\[a = \frac{{{\sigma _{xy}}}}{{\sigma _x^2}}\;{\rm{et}}\;b = \overline y - a\overline x \]
\(a\) est le coefficient de régression (c'est aussi le bêta de l'analyse financière) et \(b\) est la constante de régression (intercept). Il est démontré que ce sont les meilleurs estimateurs en page moindres carrés.
Pour Excel, \(a\) correspond à la fonction PENTE et \(b\) à la fonction ORDONNEE.ORIGINE. On les obtient ensemble par la fonction DROITEREG qui reprend les principaux paramètres d’une régression.
Selon la dispersion des points autour de la droite, l’ajustement peut être de plus ou moins bonne qualité. Il est mesuré par les coefficients de corrélation (\(r\)) et de détermination (\(R^2\)).
Note : la RLS peut être utilisée pour des relations apparemment non linéaires mais transformables en fonctions affines par un changement de variable (voir régression sur tendance exponentielle). En pratique, n'importe quel logiciel réalise des régressions non linéaires.
Interprétation
Si le coefficient de corrélation est suffisamment élevé, le modèle peut-être utilisé pour des applications prédictives ou prévisionnelles. On remplace alors la variable \(x\) par une valeur choisie et l’équation de la droite nous fournit pour cette valeur une estimation de la variable expliquée. En général, on procède à une extrapolation : graphiquement, on prolonge la droite.
Toutefois, le modèle peut être meilleur si l’équation d'une courbe remplace celle de la droite (lorsque le nuage de points présente une forme de banane), ou si l'on ajoute une deuxième variable explicative. Outre la connaissance « métier » du sujet, c’est l’observation des résidus qui doit mettre la puce à l’oreille (voir hypothèses de validité de la régression linéaire).
Exemples
Surtout ne manquez pas les pages d'exemple d'ajustement (niveau terminale maths complémentaires), de RLS avec calculatrices, ainsi que les calculs des paramètres d'une RLS et l'exemple de RLS avec Excel. Voir aussi une sortie de Statistica en page de coefficient de corrélation et un état de XLSTAT en page de Durbin-Watson.
