Ajustement linéaire (maths complémentaires)
Vous découvrirez ici le principe de l’ajustement linéaire à partir d’un exemple. Les aspects théoriques qui sont décrits sont exigibles au programme de terminale générale, maths complémentaires.
Une série à deux variables
Le taux de départ des Français en vacances a peu évolué depuis 1985. Auparavant, la hausse était continue. Les chiffres qui suivent avaient fait l’objet d’un problème au bac B en 1985, à une époque optimiste, où l’on pensait que la tendance allait se prolonger…
| Années | 1978 | 1979 | 1980 | 1981 | 1982 | 1983 |
| Taux de départ | 54,3 | 56,0 | 56,2 | 57,2 | 57,8 | 58,3 |

Représentons cette série avec un nuage de points. Le temps figure toujours en abscisse. Si vous êtes en présence d’un autre type de données, c’est la variable qui pourrait expliquer l’autre que vous placez en abscisse (pour la repérer dans un énoncé, c'est la première ligne du tableau).
En l’absence d’indications, c’est à vous de choisir les intervalles de vos axes. Ils ne se croisent donc pas à l’origine, comme si vous étudiiez une courbe représentative d’une fonction.
Quand on calcule sans ordinateur, comme c’est le cas par exemple lors d’une épreuve du bac, on procède toujours à un changement de variable lorsqu’on travaille sur des années. Ainsi nous considérerons que l’année 0 correspond à 1977.
Sur ce nuage nous représentons aussi le point moyen, que nous appellerons \(G.\) Soit \(n\) le nombre d’observations.
\(x_G = \frac{x_1 + x_2 + … + x_n}{n}\)
\(y_G = \frac{y_1 + y_2 +…+ y_n}{n}\)
Donc ici \(x_G\) \(=\) \(\frac{1+2+3+4+5+6}{6}\) \(=\) \(3,5\)
\(y_G\) \(=\) \(\frac{54,3+56+56,2+57,2+57,8+58,3}{6}\) \(≈\) \(56,6\)
Ainsi \(G(3,5\, ;56,6)\)
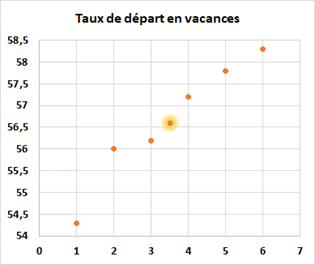
Le point moyen a été représenté avec un halo particulièrement décoratif.
Notez au passage que la série de taux de départ aurait pu être considérée comme série à une variable, à partir de laquelle nous aurions pu établir moyenne, médiane, etc. C'est bien la problématique qui nous fait considérer cet exemple comme série à deux variables.

La covariance
La covariance entre deux variables statistiques \(x\) et \(y\) se calcule de deux façons. Il existe aussi diverses notations : on l'écrit \({\rm{Cov}}(x,y)\) ou \(σ_{xy}\)
Par définition :
\[{\rm{Cov}}(x,y) = \frac{1}{n}\sum\limits_{i = 1}^n {({x_i} - {x_G})({y_i} - {y_G})} \]
Sinon, la formule de König…
\[{\rm{Cov}}(x,y) = \frac{1}{n}\sum\limits_{i = 1}^n {{x_i}{y_i}} - {x_G}{y_G}\]
Avec la première formule, le calcul ressemble à ceci (les données sont en gris et les calculs en bleu, réalisation avec Excel) :
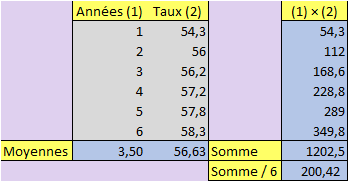
D’où \(200,42 - (3,5 × 56,63) = 2,2\)
Avec la seconde formule, le calcul devient le suivant :
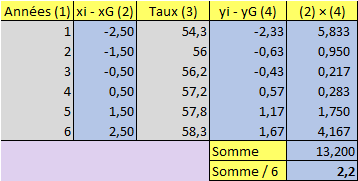
La droite des moindres carrés
La droite d’ajustement est celle qui résume le mieux le nuage de points. Elle permet d’extrapoler une tendance dans le futur, par exemple. Il en existe plusieurs versions mais celle que l’on trouve dans la quasi-totalité des études est la droite des moindres carrés.
Graphiquement, appelons « résidus » les écarts qui existent entre les points du nuage (représentant les données) et la droite (le résumé théorique du nuage). La droite des moindres carrés est celle qui minimise les carrés des résidus. En page de droite des moindres carrés, vous en avez une illustration (attention, le texte de cette page est parfois d’un niveau supérieur à la terminale).
Le coefficient directeur de cette droite (appelé coefficient de régression) s’obtient de la façon suivante :
\(a = \frac{\rm{Cov}(x,y)}{V(x)}\)
Vous conviendrez que le calcul manuel de la variance et de la covariance n’est pas un moment de pur bonheur (sinon vous êtes trop bizarre). En page de régression avec calculatrices vous avez les modes d’emploi avec Casio et TI.
Nous trouvons \(y = 0,754x + 53,99.\) Nous avons choisi de réduire la variable « année » mais pas le taux. Nous aurions pu faire l’inverse, réduire les deux variables ou au contraire aucune, nous aurions de toute façon obtenu un coefficient de 0,754. Seule l’ordonnée à l’origine est affectée par le changement de variable.
Le coefficient de corrélation
Le coefficient de corrélation s’obtient en divisant la covariance par le produit des écarts-types. Il est compris entre -1 et 1. Plus il est éloigné de zéro, meilleure est l’approximation par la droite des moindres carrés. Le calcul manuel est encore plus long que celui du coefficient de régression (vu qu’il y a une variance supplémentaire puis des racines carrées). Ici, nous trouvons un très bon coefficient de 0,974.
