Théorème de Bayes et fonction de coût
Voici un sujet intéressant qui fait le lien entre les probabilités et l'analyse de données. Sa connaissance est requise pour étudier les techniques d’apprentissage supervisé, en particulier l’analyse discriminante probabiliste.
Problématique
Le challenge consiste à prendre la meilleure décision dans une situation incertaine mais avec l’aide d’une loi de probabilité.
Nous nous contenterons ici de situer la problématique sans chercher à résoudre quoi que ce soit.
Si les utilisations sont nombreuses, c’est surtout le scoring qui, en entreprise, offre un terrain d’application privilégié à la règle de décision de Bayes (Bayes’ decision rule). Les techniques de ciblage pour le marketing peuvent également recourir à cette approche.
Cette règle de décision est un prolongement du théorème de Bayes, lui même application des probabilités conditionnelles telles qu'enseignées au lycée (c'est-à-dire la formule à appliquer dès qu’un énoncé commence par « sachant que »). Ci-dessous, portrait de Thomas Bayes généré par Ideogram, logiciel d'IA.

Ce théorème est employé dans le cadre du scoring : sachant que tel demandeur de crédit exerce la profession de cracheur de feu, qu’il est sans domicile fixe, qu'il est âgé de 99 ans, etc. et que des probabilités de non-remboursement ont été affectées à toutes ses caractéristiques (déterminées sur la base de données de la clientèle), combien nous coûtera en moyenne ce dossier si le demandeur n’honore pas tous ses engagements ?

On va prendre la décision de classer cet individu parmi les deux ou trois groupes qu’on a jugé utile de former (scores rouge, orange et vert, par exemple) mais bien sûr avec un risque d’erreur. Risque calculé, certes, mais risque quand même. Cette erreur d’affectation représente un « coût », financier ou non : si la méthode est utilisée dans le domaine médical, le « coût » n’est pas monétaire ; ce peut être une simple gêne du patient ou… la mort.
Illustration
Soit une fonction de score connue partagée en trois zones. Les mauvais dossiers sont très rares, les dossiers « moyens » le sont moins et ceux qui ne rencontrent jamais le moindre incident sont les plus fréquents. On constate des probabilités sur les dossiers déjà terminés ou en passe de l’être, et qui peuvent se répartir ainsi :
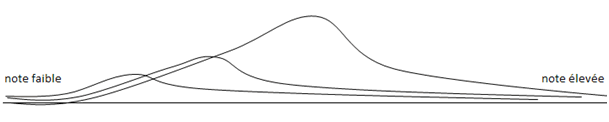
Tout l’art consiste à placer au mieux les deux limites sur cet axe (vert-orange et orange-rouge) mais d’autres paramètres entrent en jeu.
Établir une fonction de coût (ou de perte) consiste à attribuer une valeur à chaque erreur. Une utilisation habituelle de ces fonctions est de les coupler avec les matrices de confusion dans la phase de validation des méthodes de classification supervisée. Ceci permet de moduler les règles d'appartenance à un groupe.
La démarche consiste à pondérer ces probabilités conditionnelles par des coûts et à choisir celle qui les minimise. Il s’agit de la règle de décision de Bayes.
Dans le cas du scoring d’octroi, il s'agit plutôt d'une fonction de résultat à maximiser. On établit le coût moyen d’un dossier accepté qui termine sa course au service du contentieux et le bénéfice moyen d'un dossier sans histoire. On doit en outre évaluer le manque à gagner d’un dossier bêtement refusé alors qu’il n’aurait posé aucun problème. Ces évaluations comportent toujours une part d’arbitraire...
Pour simplifier, le tableau ci-dessous ne traite que deux cas. De plus, il se situe dans une problématique de coût et non de résultat. Dans notre exemple de scoring sur trois couleurs, le tableau aurait bien sûr neuf cases.
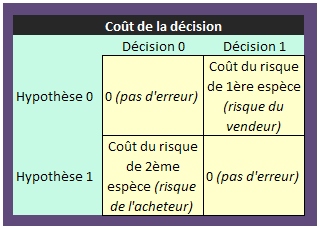
Dans cette logique, une fonction de score ne cherche pas à séparer au mieux les individus ou les dossiers selon leurs propres caractéristiques mais à minimiser les coûts de mauvais classements, ce qui peut conduire à des résultats très différents.
Ce qu’il faut bien voir, c’est que la densité de probabilité a nécessairement la même pondération pour chaque groupe, que celui-ci présente une rareté ou qu’il soit très commun.
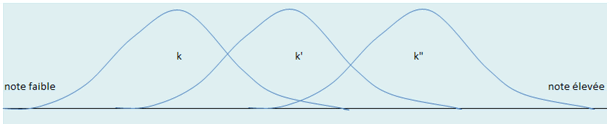
Ceci permet d’introduire les probabilités conditionnelles puisque pour une note de score \(x\) donnée (sur l’axe des abscisses), on obtient une probabilité de tomber dessus si l’on se trouve dans la première « bosse », une autre si l’on se situe dans la deuxième et encore une autre si l’on est dans la troisième. Si l’on nomme \(k\) l’une de ces bosses, la probabilité conditionnelle de se trouver dans \(k\) sachant \(x\) est donc égale à \(P(k/x).\)
Le coût
Cette probabilité conditionnelle doit être multipliée par une autre condition, qui n’est pas calculée mais déterminée par avis d’expert, et qui est la fonction de coût (coût d’avoir choisi \(k\) alors qu’aurait dû choisir \(k'\)).
Et ce n’est pas fini.
Non seulement \(P(k/x)\) doit être affecté à un coût, mais \(k\) doit être pondéré selon qu’il a de bonnes chances de se produire ou non (les \(P(k)\) sont illustrées par le premier graphe en haut de page).
En page de théorème de Bayes, vous trouverez cette formule :
\(P(C_1/B)\) \(=\) \(\displaystyle{\frac{P(C_1)P(B/C_1)}{P(B/C_1)P(C_1) + P(B/C_2)P(C_2) + P(B/C_3)P(C_3)}}\)
Adaptons-la :
Espérance de coût si \(k\) sachant \(x\) \(=\) \(\displaystyle{\frac{P(k)P(x/k)}{\sum_{i=1}^{3}P(x/k_i)P(k_i)} \times}\) coût associé.
Nous avons vu que tout l’art consistait à placer les limites entre ce qui devait relever de \(k,\) de \(k’\) et de \(k’’.\) Ce placement est donc celui qui minimise l’espérance de la fonction de coût.
