Validation par table d'affectation
Il existe d’épatantes techniques statistiques ou d'analyse de données pour classer l'effectif d'une population. Contexte : on dispose de données supposées explicatives (caractères démographiques, réponses à une enquête…) et d'un critère qualitatif à « prédire ». Celui-ci est par exemple la fidélité d’un consommateur à une marque et il peut être soit binaire soit modulé selon plusieurs modalités. Quant aux données explicatives dont on dispose sur ce consommateur, ce peut être son âge, le montant de ses achats, sa région, etc.
Plusieurs techniques
Les techniques utilisées dépendent de la nature des variables explicatives (qualitatives et/ou quantitatives). Mentionnons l’analyse factorielle discriminante (AFD), l’analyse discriminante prédictive, la régression logistique, les arbres de décision, les réseaux de neurones, les algorithmes génétiques… Mais la technique dépend aussi du but recherché : dans notre exemple, ce peut être de prédire si tel consommateur sera ou non fidèle en fonction des informations dont on dispose sur lui, d’établir le profil-type du consommateur versatile, d’évaluer l’importance relative des variables explicatives…

Validation
Évidemment, le classement dans un groupe, réalisé par un outil statistique ou de machine learning, ne sera pas parfait. On peut classer les clients d’un disquaire et constater que le rap trouve beaucoup d’amateurs dans la tranche d’âge 16-25 ans, il n’empêche qu’un septuagénaire peut très bien aimer le rap. Pourtant, on peut parier une inversion de matrice contre un dîner chez Maxim’s que n’importe quel outil statistique utilisant les données du disquaire l’aura catalogué comme « non amateur ».
C’est pourquoi les résultats d’une classification supervisée doivent toujours être validés. Non seulement cette étape permet de vérifier que le modèle présente une bonne capacité de généralisation, mais elle permet aussi de comparer les résultats de plusieurs techniques afin de privilégier la plus adaptée.
Si la population statistique est suffisamment importante, elle est séparée en deux pour l’analyse : une partie est utilisée pour les calculs (échantillon d’apprentissage) et l’autre l’est pour la validation (échantillon de test). Il n’existe pas de proportions types, tout dépend de la taille de l’échantillon et de la méthode employée.
Là aussi, plusieurs techniques de validation existent et se complètent. La plus simple consiste à établir une matrice de confusion ou table d’affectation, de laquelle on déduit un taux de bons classements théorique. Si deux groupes seulement sont en lice, elle se présente sous la forme d'un simple tableau à quatre cases.
Exemple
Une illustration figure ci-dessous. Il s’agit d’une matrice de confusion générée par une AFD sur XLSTAT à partir de l’échantillon d’apprentissage. Pour information, le reste de l’étude se trouve en page exemple d’une AFD descriptive. En général, on place les réalisations en colonne et les prédictions en ligne mais ce n’est pas le cas avec ce logiciel.
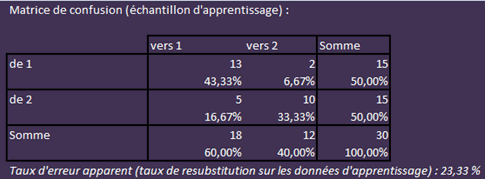
Nous analysons un échantillon de trente automobilistes dont la moitié envisage un changement de véhicule. L’AFD a correctement reclassé 23 d’entre eux. Le taux de bons classements s’établit donc à \(76,7\,\%.\) Il doit être comparé au taux de \(50\,\%\) qui correspond, dans le cas où l’on ne retient que deux groupes de même taille, à une répartition au hasard.
Est-ce un bon résultat ? Apparemment, il n’a rien de fracassant. Mais du seul point de vue statistique il est impossible de se prononcer. Selon la problématique, on peut s’intéresser essentiellement au bon classement dans un seul des groupes. En pratique, il faut coupler la matrice de confusion avec une fonction de coût pour que le manageur estime si le modèle est acceptable ou non. Dans notre exemple, les individus du groupe 1 (automobilistes ne souhaitant pas changer de véhicule) sont beaucoup mieux classés que ceux de l’autre groupe.
Si le modèle n’est pas satisfaisant en l’état, on peut se contenter de déplacer le curseur qui sert de frontière entre les deux groupes. Ici, la limite est 0 (valeur de la variable canonique de l’AFD). Si la variable prend une valeur négative, le modèle laisse supposer que l’automobiliste ne souhaite pas changer de véhicule. Observons le détail par individu tel qu’il est restitué par XLSTAT.
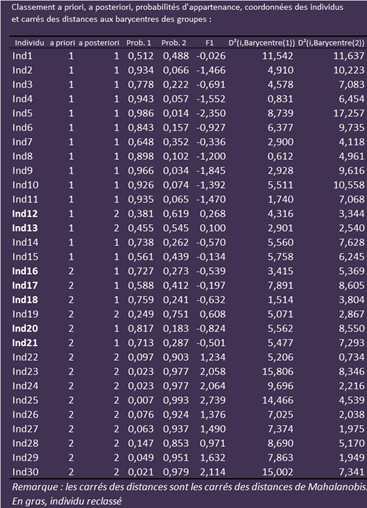
Et si l’on déplaçait le curseur à -0,6, qu’observerions-nous ? D’abord qu’il y aurait vingt-deux individus bien classés au lieu de vingt-trois (nous vous laissons le vérifier). Mais aussi que treize automobilistes du groupe 2 seraient correctement classés au lieu de dix. Donc, si le coût d’un mauvais classement en groupe 2 est plus élevé qu’en groupe 1, il peut être intéressant de reconsidérer la frontière du modèle et de la décaler de 0 vers -0,6 même si la performance globale est moins bonne qu’elle ne l'était dans une optique purement statistique.