Coefficient de Kendall et test
Munissons-nous d'une distribution à deux variables. Généralement, la mesure d’une plus ou moins bonne corrélation entre elles est effectuée avec le coefficient de corrélation de Pearson, au besoin en utilisant un changement de variable si la liaison n’est pas linéaire.
De l'utilité du coefficient de Kendall
Parfois hélas, cet outil habituellement salvateur devient inopérant : variables ordinales, discrètes, ne suivant pas une loi normale, etc. On se tourne alors vers une corrélation des rangs. L’objet de l’étude n’est plus les valeurs que prennent les observations mais leur classement par rapport à l’ordre observé sur l’autre variable.
Un coefficient souvent utilisé est alors celui de Spearman. Mais ce dernier n’est pas toujours très pertinent, en particulier lorsqu’il existe beaucoup d’ex-æquo. Il reste une solution : le coefficient des rangs de Kendall (Kendall rank correlation coefficient).
Technique
Le principe est le suivant : une première série est triée et les rangs des valeurs de la deuxième série sont mis en regard de la première. Dès lors, on ne s’intéresse plus qu’à la seconde. Pour chaque observation, on relève le nombre de valeurs suivantes lui sont supérieures (on attribue +1) et inférieures (-1). D’où une nouvelle série de chiffres qui sont des soldes entre des nombres positifs et négatifs.
Le solde total \(S\) est égal à \(\frac{{n(n - 1)}}{2}\) si l’ordre est parfaitement respecté puisque c’est la somme des \(n\) premiers entiers naturels. Si l’ordre est parfaitement inversé, \(S = \frac{{-n(n - 1)}}{2}.\) En cas d’indépendance totale, \(S = 0.\)
La valeur de \(S\) est alors observée au travers de ce bel instrument qui est le « tau de Kendall » (ne pas confondre la lettre grecque tau avec un taux, même si l'on a bien ici un quotient !). Celui-ci est le solde observé par rapport au solde maximum :
\[\tau = \frac{S}{{\frac{{n(n - 1)}}{2}}}\]
\[\Leftrightarrow \tau = \frac{{2S}}{{n(n - 1)}}\]
C’est donc un indicateur assez « rustique ». Il est compris entre -1 et +1 et s’interprète comme un coefficient de Pearson. : plus il s’approche de 1, plus on est certain qu’il existe une corrélation positive (variations dans le même sens), plus il est proche de -1 et plus on peut supposer l’existence d’une corrélation négative. Enfin, si le \(\tau\) de Kendall est proche de zéro, la probabilité qu’il n’existe aucune liaison monotone entre les deux est forte. Par « liaison monotone », il faut entendre une liaison linéaire, logarithmique, exponentielle… Graphiquement, on ne sait pas quelle forme peut avoir la courbe de régression mais ce n’est pas l’objet de l’étude.
Comme il est calculé sur des variables aléatoires, ce coefficient en est lui-même une. Son espérance est nulle et sa variance est égale à :
\[V(\tau ) = \frac{{2(2n + 5)}}{{9n(n - 1)}}\]
Ainsi, \(\tau\) tend assez rapidement vers une loi normale (selon les auteurs, on estime que huit à dix observations suffisent). Bien qu’il existe une table du \(\tau\) de Kendall, elle n’est guère utilisée puisque la significativité du coefficient peut être estimée par un banal test paramétrique. Pour être comparé aux valeurs prises par la loi normale centrée réduite, on applique bien sûr le même sort au \(\tau\) : le centrage étant réalisé implicitement puisque l’espérance est nulle, il suffit pour réduire le coefficient de le diviser par son écart-type :
\[z = \frac{\tau }{{\sqrt {\frac{{2(2n + 5)}}{{9n(n - 1)}}} }} \leadsto \mathscr{N}(0\,;1)\]
Sous l’hypothèse nulle, les classements sont indépendants. Sous l’hypothèse H1, ils sont corrélés.
Exemple (sur variable ordinale)
Une entreprise souhaite mettre sur le marché un nouveau produit alimentaire.

Des clients potentiels goûtent dix versions de ce produit qui correspondent à des taux de lipides différents. Les clients notent ensuite chaque version. Une fois agrégées sur l’ensemble des goûteurs, ces notes ne sont pas étudiées en tant que telles mais sont classées de façon à obtenir un ordre global de préférences. On souhaite savoir si ce classement peut être lié au taux de lipides.
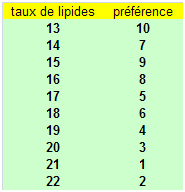
La première colonne du tableau est déjà triée. On observe maintenant la seconde.
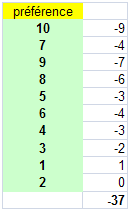
Explications : après la première valeur du classement (soit 10), combien sont plus petites ? 9. Combien sont plus grandes que 10 ? Aucune. On obtient donc -9. Après la deuxième donnée (7), 6 valeurs sont inférieures et 2 sont plus élevées (le 8 et le 9). Le solde s’établit donc à -4. Et ainsi de suite. La somme des écarts est égale à -37.
Premier enseignement, la somme des écarts étant négative, les deux classements varient en sens inverse. Les versions préférées des goûteurs sont celles où le taux de lipides est le plus élevé.
Deuxièmement, il convient de mesurer la corrélation sur une échelle de -1 à 1. Le \(\tau\) de Kendall entre en scène. L’application de sa formule donne -0,822. La liaison semble donc assez forte.
Troisièmement, peut-on affirmer que cette liaison est forte pour un risque donné de se tromper ? C’est ici que le test intervient. Nous ne procéderons qu’au seul test paramétrique.
Pour un effectif de 10, l’écart-type du \(\tau\) de Kendall s’élève à 0,2485. Donc, la statistique \(z\) s’établit à -3,309. C’est le genre de valeur qu’on trouve tout en bas des tables de répartition de la loi normale, de celles qui est impossible à dépasser… Et on rejette l’hypothèse d’indépendance H0.
Ci-dessous, l’état de sortie de XLSTAT montre, sous forme de matrices, d’abord le \(\tau\) de Kendall, ensuite la p-value qui est, au cas où H0 serait vérifiée, la probabilité que \(z\) soit inférieure à la statistique théorique. Ici, elle est quasi nulle ce qui nous autorise à rejeter H0. Enfin, la dernière matrice indique les carrés des coefficients de Kendall.
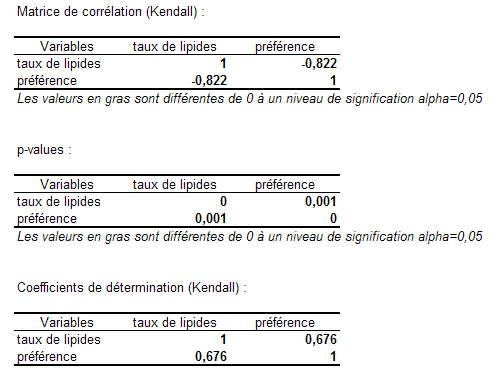
Conclusion : nous pouvons être certains que plus le taux de lipides du produit est élevé, du moins dans la fourchette testée par les goûteurs, plus ce produit est apprécié.
