Coefficients de Spearman et de Kendall
Pour valider l'existence d'un lien entre deux variables, on réalise ordinairement une régression linéaire simple, voire une régression non linéaire. La qualité du lien supposé est mesurée par le coefficient de corrélation (dit « de Pearson »). Cependant, il existe des situations pour lesquelles une mesure de la corrélation sur les valeurs est inadaptée. Si les variables sont ordinales, discrètes, ou si des outliers risquent de biaiser les résultats, ou encore que les valeurs en elles-mêmes n’ont que peu d’importance, ou enfin qu’elles ne suivent pas une loi normale, il nous reste un joker : les corrélations des rangs.
Les rangs
On n’utilise alors pas les valeurs des observations dans les calculs mais leur RANG.
S’il existe déjà un tri, par exemple les dates d’une série chronologique, les valeurs que prend la variable triée sont remplacées par leur numéro d’ordre croissant, et c’est sur ces rangs que la corrélation est effectuée. Illustration :
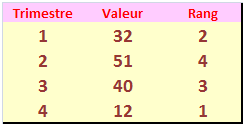
Ce tableau présente une série déjà ordonnée (les trimestres). Dans quelle mesure la première colonne ressemble-t-elle à la troisième ?
Si l’on examine une liaison entre des données NON temporelles, par exemple les notes attribuées à un produit par deux groupes de testeurs, il faut bien sûr commencer par TRIER les notes de l’un des deux groupes, leur affecter un numéro d’ordre croissant puis remplacer les valeurs correspondantes de la seconde série par leur rang (ou inversement).
Avec ce type de méthode, on perd évidemment de l'information. Du coup, on cherche juste à savoir dans quelle mesure l’évolution est conjointe ou non. La FORME de la liaison, linéaire ou non, ne peut pas être observée. En revanche, l’EXISTENCE d’une liaison monotone même non linéaire est très bien perçue.
Il existe plusieurs techniques concurrentes et donc plusieurs coefficients de corrélation possibles pour en valider les résultats. Les plus connus sont celui de Spearman et celui de Kendall. L’opération se déroule en deux temps : d’abord le calcul du coefficient et ensuite le test pour savoir si ce coefficient peut être considéré ou non comme significatif.
Le calcul d’un coefficient et le test afférent peuvent être réalisés avec un tableur (voir notamment « Statistiques avec Excel », de J.-P. Georgin et M. Gouet, PUR 2005 ch.15).
Le coefficient de corrélation de Spearman
Ce coefficient, appelé \(\rho\) (rhô) ou \(r_s\), est calculé de la façon suivante (\(d_i\) étant la différence entre le rang de l’observation \(i\) et celui de sa valeur) :
\[\rho = 1 - \frac{{6\sum\limits_{i = 1}^n {d_i^2} }}{{{n^3} - n}}\]
Cette formule est issue du coefficient de corrélation linéaire de Pearson, mais appliqué aux rangs.
Exemple avec Excel :
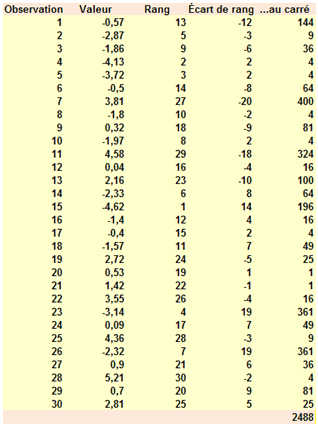
Ce tableau parle de lui-même et illustre le mécanisme. La somme des écarts de rangs élevés au carré s'établit à 2 488. En utilisant la formule ci-dessus, on trouve un coefficient de 0,446.
Selon S. Tufféry (Data mining et statistique décisionnelle, Technip 2007, p. 495), même si les variables sont continues, « on a toujours intérêt à comparer les deux coefficients de Pearson et Spearman, le plus fiable étant le second », notamment pour détecter des liaisons non linéaires (le coefficient de Spearman étant alors plus fiable que celui de Pearson).
Pour savoir si la valeur du coefficient permet de supposer une corrélation, voir la page test du coefficient de Spearman.
Le coefficient de Kendall
On établit une statistique « tau » (\(\tau\)). La construction est la suivante :
On trie la première colonne et on la compare au rang de la seconde série de valeurs (comme prédemment). Mais ici, pour chaque rang de cette seconde colonne, on compte combien de valeurs suivantes lui sont supérieures (on attribue +1) et inférieures (-1). D’où une nouvelle série de valeurs qui sont des soldes entre des nombres positifs et négatifs. La somme de ces soldes, que l'on nommera \(S\), est ensuite comparé au solde maximal qui serait obtenu avec une parfaite corrélation.
\[\tau = \frac{S}{{\frac{{n(n - 1)}}{2}}}\]
\[ \Leftrightarrow \tau = \frac{{2S}}{{n(n - 1)}}\]

Le \(\tau\) s'interprête comme les autres coefficients de corrélation. Un test permet d'infirmer ou non l'hypothèse d'indépendance. Il existe un test ad hoc mais, comme ce coefficient est une variable aléatoire qui suit une loi normale sous des conditions très peu restrictives, on procède plutôt à un test paramétrique.
Pour information, le \(\tau\) s'établit à 0,32 dans l'exemple ci-dessus.
La procédure est détaillée en page corrélation de Kendall.
Pour conclure...
S. Tufféry (op cit. p. 496) mentionne une liaison entre le \(\tau\) de Kendall et le \(rho\) de Spearman (formule de Siegel et Castellan) : \(-1 \leqslant 3 \tau - 2 \rho \leqslant 1.\)
Le principal écueil de ce type de corrélation est le traitement des ex-æquo. S’ils sont nombreux, le résultat peut ne dépendre que d’une convention sur la façon de les traiter. Selon les spécialistes, cet inconvénient serait mieux traité par le \(\tau\) de Kendall que par le \(\rho\) de Spearman.
Précisons enfin que ces coefficients ont aussi leur utilité dans le cadre d'études multivariées, certains logiciels autorisant la réalisation d'une matrice de corrélation des rangs avec l'un ou l'autre de ces coefficients. Une telle matrice permet alors de réaliser une analyse en composantes principales sur les rangs (voir en page ACP des rangs un exemple où le coefficient de Spearman permet une meilleure ACP que celui de Kendall).
