CAH sur individus
- Au cours du [dix-huitième] siècle, grâce aux réflexions philosophiques d'Emmanuel Kant qui affirmait que la représentation rendait l'objet possible, et non le contraire, il se forgea l'idée qu'il était impossible d'argumenter sur la connaissance ou la réalité sans tenir compte du fait que c'était l'esprit humain qui construisait cette réalité ou cette connaissance. Cela conféra à la science de la représentation et de la visualisation des données l'importance essentielle qu'elle méritait. (Intelligence, machines et mathématiques - L'intelligence artificielle et ses enjeux, coll. Le monde est mathématique, RBA 2020).
La classification ascendante hiérarchique (CAH) n’est pas la technique d'analyse de données la plus ancienne mais la problématique de la classification date de quelques milliers d’années, du moins dans sa version généalogique ! En entreprise, c’est essentiellement un outil au service du marketing.
La démarche
La CAH organise les observations, définies par un certain nombre de variables, elles-mêmes divisées en modalités, en les regroupant de façon hiérarchique. Elle commence par agréger celles qui sont les plus semblables entre elles, puis les observations ou groupes d’observations un peu moins semblables et ainsi de suite jusqu’au regroupement trivial de l’ensemble de l’échantillon. Ces agrégations se font deux à deux.
C’est parce que cette technique part du particulier pour remonter au général qu’elle est dite « ascendante » ou agglomérative. Cette démarche est à l’inverse de techniques beaucoup moins utilisées en analyse de données et surtout à l’inverse du schéma mental auquel on se réfère pour classer nos fichiers sur disque dur ou pour chercher un livre dans une bibliothèque.
Représentation graphique
Les liens hiérarchiques apparaissent sur un dendrogramme tel que celui présenté ci-dessous (XLSTAT) :
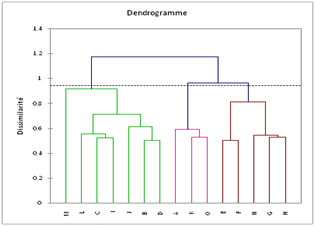
Cet outil visuel est épatant. Le dendrogramme, ou arbre hiérarchique, montre non seulement les liaisons entre les classes mais la hauteur des branches nous indique leur niveau de proximité. Toutefois, contrairement aux problématiques scientifiques (zoologie, botanique…), on se préoccupe très rarement des liens de filiation qui existent entre les clusters dans le champ des sciences humaines ou des sciences de gestion.
Aspects techniques
Les observations sont décrites par des valeurs numériques qui sont centrées et réduites s’il existe une différence d’échelle.
Selon le degré de perfectionnement de votre logiciel, vous aurez ou non à choisir une métrique pour juger de la proximité entre observations. Toutefois, la CAH n’utilise pas une métrique mais deux. En effet, cette technique repose sur la mesure d’une distance entre clusters. Et là aussi, il y a le choix.
En fonction des options retenues, les résultats peuvent être complètement différents. C’est pourquoi il est utile de faire précéder la CAH d’une analyse factorielle qui donne des indications sur la structure de l’échantillon. Cette multiplicité des choix laisse entrevoir les limites de la CAH : reposant sur des fondements mathématiques « faibles », elle nécessite le soutien d’autres techniques pour être tout à fait opérationnelle.
C’est soit la configuration du dendrogramme, soit un nombre de clusters prédéfini qui permet de tracer une coupure (ici en pointillés) à un certain niveau d’agrégation. Elle détermine le nombre de classes retenu pour la suite des évènements. Quelques logiciels délimitent la « meilleure » coupure. C’est le cas sur le dendrogramme ci-dessus. De prime abord, la césure semble mal située car elle se trouve entre deux nœuds quasi ex-æquo mais si elle avait été placée un peu plus bas, elle aurait généré une classe comprenant un seul individu.
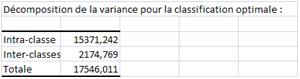
Le dendrogramme et le diagramme de niveau des nœuds permettent d'établir un bon compromis entre dispersions intra et interclasses, ainsi que la courbe du \(R^2\) en fonction du nombre de clusters. Une ANOVA sur un critère qui nous intéresse particulièrement permet de vérifier que les classes sont suffisamment individualisées.
Parfois, on ne peut rien tirer d’une CAH. Ci-dessous, vingt individus ont été classés avec vingt variables dont les valeurs ont été générées aléatoirement (XLSTAT) :
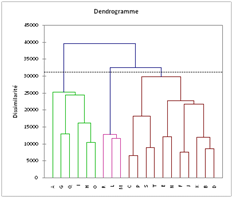 |
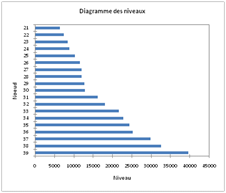 |
Très bien mais...
En conclusion, cet examen visuel fait de la CAH un outil plus pratique que les k-means mais cette technique de classification reste assez délicate à paramétrer. Par ailleurs, si l'effetif à classifier est très important, le temps de calcul peut se révéler long. Nous avons alors le choix d’échantillonner ou d'identifier un nombre restreint de groupes par une autre technique puis de procéder sur ceux-ci à une CAH (classification mixte). La plus ou moins bonne qualité de la classification peut être estimée avec une analyse factorielle discriminante.
