Estimation ponctuelle et par intervalle
Cette page est sans doute plus théorique, plus « matheuse » que la plupart des pages de statistiques de ce site. Il en faut pour tout le monde.
Sa trame est inspirée d’un cours de P. Sylvestre-Baron (1985).
Statistique inférentielle
Grosso modo, la statistique se compose de deux branches : descriptive et inférentielle.
La statistique descriptive analyse un échantillon ou une population. L'inférence va plus loin puisqu'elle extrapole ce qui est observé sur un échantillon à l'ensemble de sa population de référence.
Reprenons la définition de la statistique inférentielle selon F. Dress (Probabilités et statistiques de A à Z, Dunod 2004) : « partie de la statistique qui analyse, dans un cadre explicitement probabiliste, des données préalablement recueillies de façon à en déduire les paramètres des lois de probabilité et à tester la validité du modèle ainsi reconstitué ».
Cette branche se divise en deux types de méthodes : l’estimation, que nous présentons ici, et la théorie des tests.
L'estimation
À partir d'un échantillon aléatoire, nous devons estimer un paramètre d'une population que nous n’avons pas les moyens de connaître. C’est par exemple la moyenne d'une variable statistique sur une population d'un million. Il s’agit donc bien d’une moyenne inconnue \(m\) et non d’une espérance. Par la suite nous appellerons tout paramètre inconnu \(\theta .\)
En raison des fluctuations d'échantillonnage, nous pouvons considérer les observations comme des variables aléatoires (v.a).
Il existe deux façons d’estimer ce paramètre.
- On peut estimer sa valeur. C’est une estimation ponctuelle.
- On peut établir un intervalle dans lequel il devrait se situer. C’est une estimation par intervalle de confiance.
Échantillon bernoullien
Un échantillon bernoullien de taille \(n\) est un ensemble de \(n\) v.a indépendantes entre elles qui suivent toutes la même loi de probabilité : \(X_1,\) \(X_2,\) \(…,\) \(X_i,\) \(…\) \(X_n.\)
L’ensemble des réalisations est l’échantillon d’observations \((x_1,\) \(x_2,\) \(…\) \(x_i,\) \(…\) \(x_n).\)
Soit \(X_i\) une v.a discrète. Pour tout \(i\) compris entre 1 et \(n,\) la probabilité que \(x_i\) soit bien égale à \(X_i\) est fonction de \(x_i\) mais aussi de \(\theta .\)
\(P(X_i = x_i) = f(x_i, \theta )\)
Si \(X_i\) est une v.a continue, notre écriture devient :
\(P(x_i \leqslant X_i \leqslant x_i + dx_i) = f(x_i, \theta)dx_i.\)
L’estimation ponctuelle
Nommons \(\hat \theta \) l’estimation que nous ferons de \(\theta .\)
Cette estimation nous est donnée par un estimateur \(T_n,\) construit à partir d’une statistique d’échantillon qui est fonction des observations.
\(\hat \theta = T_n(x_1, x_2, …, x_i, …, x_n)\)
Nous l'avons vu, ces observations sont considérées comme des v.a. L'estimation est donc fonction de l'échantillon bernoullien.
Un peu abusivement, nous pouvons réécrire :
\(\hat \theta = T_n(X_1, X_2, …, X_i, …, X_n)\)
Donc \(\mathop {\lim }\limits_{n \to \infty } {T_n} = \theta \)
Pour choisir le meilleur estimateur du paramètre inconnu, il existe plusieurs méthodes. La plus habituelle est celle du maximum de vraisemblance. Un bon estimateur doit être sans biais et convergent (détails en page d’estimateur).
On dit qu’un estimateur sans biais est plus efficace qu’un autre si sa variance est plus petite.

L’estimation par intervalle de confiance
Soit \(\eta\) un nombre fixé compris entre 0 et 1. Pour toute réalisation sur un échantillon \((x_1,\) \(x_2,\) \(…\) \(x_i,\) \(…\) \(x_n)\) on associe une probabilité que l’intervalle aléatoire \(I(X_1,\) \(X_2,\) \(…\) \(X_i,\) \(…\) \(X_n)\) contienne \(\theta\) doit être supérieure ou égale à \(\eta.\)
\(\forall \theta,\) \(P{\theta \in I(X_1, X_2, … X_i, … X_n} \geqslant \eta\)
\(\eta\) est le niveau de confiance (indépendant de \(\theta\)) et \(I\) est l’intervalle de confiance de niveau \(\eta.\)
Pour un niveau de confiance donné, on cherche l’intervalle \([A\, ;B]\) le plus resserré possible.
Soit une statistique \(Z\) qui est fonction des observations mais aussi de \(\theta.\)
\(P{a(\theta) \leqslant Z \leqslant b(\theta)} = \eta\)
\(a(\theta)\) et \(b(\theta)\) sont des fonctions monotones de \(\theta.\)
Ainsi il est équivalent d’écrire :
\(a(\theta) \leqslant Z \leqslant b(\theta)\) \(\Leftrightarrow\) \(A(x_1, x_2…x_n) \leqslant \theta \leqslant B(x_1, x_2…x_n)\)
Donc, en termes de probabilités :
\(P\{A(X_1, X_2, …, X_n) \leqslant \theta \leqslant B(X_1, X_2, …, X_n)\} = \eta\)
Si \(Z\) suit une loi discrète, l’intervalle de confiance peut ne pas être égal à \(\eta.\) Il faut alors que sa probabilité associée soit immédiatement supérieure.
Illustrons.
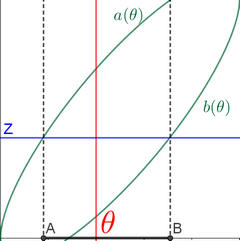
Ce graphe est un abaque (réalisé avec GeoGebra). En vert apparaissent les courbes représentatives des fonctions \(a\) et \(b\) qui dépendent de \(\theta.\) À partir de celles-ci et de la statistique d’échantillon \(Z\) on peut tracer le segment \([A, ; B]\) représentatif de l’intervalle de confiance. Dans notre exemple, le paramètre inconnu \(\theta\) se situe bien dans l’intervalle.
