Processus Moving Average (Moyennes Mobiles)
D’abord une mise en garde. Il ne faut pas confondre ce processus stationnaire avec les moyennes mobiles. En effet, le terme n’est pas très bien choisi car s’il y a bien mobilité (ce qui est la moindre des choses de la part d’un processus), il est abusif de parler de moyenne…
Problématique
Nous sommes dans le cadre d’une chronique de prévisions qui montrent des erreurs autocorrélées.
C’est dire si le sujet est pointu.
Un bon modèle, par exemple de régression multiple, ne délaisse aucune information structurée. Supposons que la fonction d’autocorrélation d’inexplicables résidus (c’est-à-dire leurs coefficients de corrélation calculés sur 1, 2… \(k\) crans) montre une ou deux valeurs sensiblement différente(s) de zéro, on va prendre son courage à deux mains et chercher à modéliser cette structure résiduelle stationnaire.
Dans un premier temps, on supposera qu’une erreur n’est corrélée qu’avec l’erreur de prévision qui l’a précédée (les \(\varepsilon\) sont des bruits blancs).
\(y_t = \varepsilon _t + \theta \varepsilon_{t-1}\)
Cette équation définit le processus MA d’ordre 1, où une valeur apparaît comme une combinaison linéaire de deux erreurs qui se suivent. Une telle formulation n’est d’ailleurs pas sans rappeler l’équation d’une droite de régression. (notez que certains auteurs et logiciels présentent la formule comme une soustraction. C’est juste une question de convention).
Soit dit en passant, le lissage exponentiel simple peut être présenté sous cette forme, \(y_t\) étant la différence entre les deux dernières observations (notre \(\theta\) étant quant à lui égal à \(1 - α\) que multiplie l’erreur \(t - 1\).
Le paramètre \(\theta\) est en principe compris entre -1 et 1. Il est estimé à partir du coefficient d’autocorrélation.
\(r_1 = \displaystyle{\frac{\theta}{1 + \theta^2}}\)

Exemple
Comment savoir si l'on se trouve devant un MA(1) ? En visualisant le corrélogramme de la série. S'il montre un net décrochage après le coefficient d'autocorrélation d'ordre 1, bingo ! Exemple ci-dessous :
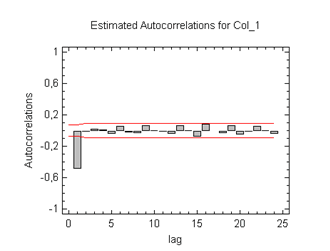
Ici, \(\theta = -0,8.\) Le logiciel qui a réalisé ce corrélogramme (Statgraphics Centurion) considère la formule en version soustractive. Sinon, la barre significative serait en zone positive.
Comment avons-nous réalisé cette oeuvre ? Avec Excel, nous avons généré 700 nombres pseudo-aléatoires suivant la loi normale centrée réduite. Il faut pour cela entrer la formule ci-dessous puis faire glisser :
=LOI.NORMALE.INVERSE(ALEA();0;1)
Sur la colonne d'à-côté, nous avons retenu la valeur obtenue sur la même ligne, moins 0,8 fois la valeur de la ligne précédente. Cliquer-glisser. Puis exportation de cette colonne de 699 valeurs dans Statgraphics et analyse descriptive de série temporelle.
Au-delà de MA(1)
Nous avons vu le processus MA(1). Mais si ce sont les \(q\) premiers coefficients d’autocorrélation qui sont significativement non nuls, nous devons établir un processus stationnaire MA(\(q\)), avec \(q\) paramètres \(\theta.\) Pour noter l’expression de MA(\(q\)), l’opérateur retard \(B\) est bien utile.
\(y_t = (1 + \theta _1 B \;+ ... +\; \theta_q B^q)\varepsilon _t\)
La partie entre parenthèses est appelée polynôme moyenne mobile.
L'horizon de prévision du modèle ne peut être supérieur à \(q,\) comme vous l’aviez deviné.
Intervalles de confiance
Par ailleurs, des intervalles de confiance peuvent être déterminés pour chaque prévision puisque l’écart-type des erreurs est connu. On peut encadrer la prévision en \(t + 1\) de \(\pm zσ\) (avec \(z = 1,96\) si \(n > 30\) et un risque bilatéral de \(5\,\%\). Exemple d’intervalle lorsque \(h = 3\) :
\(\hat{y}_{t+3} \pm z \sigma \sqrt{1 + \theta^2 _1 + \theta^2 _2}\)
Un outil bien utile
L’intérêt principal de ce processus est de le combiner avec un autre, dit autorégressif, afin d’obtenir un modèle ARMA.
Toutefois, si la démarche est bien rodée et permet une grande quantité d’options, elle est peu utilisée en entreprise où l’on se contente souvent de modèles déterministes.
