Intervalle et niveau de confiance
Chacun d'entre nous a plus ou moins tendance à généraliser. Ceux dont c’est la profession s’appellent des statisticiens. Ils emploient des techniques inductives. Les autres se fondent sur des stéréotypes. Il existe donc deux méthodes de généralisation : le jugement à l’emporte-pièce, parfois illustré par les brèves de comptoir, et les statistiques inférentielles, parfois illustrées sur ce site.
La première méthode n’est pas dénuée d’intérêt (voir la longue série d’ouvrages de J. M. Gourio, chez Robert Laffont ou aux éditions J’ai lu). Bien que jamais représentée au théâtre ou au cinéma, du moins à notre connaissance, la seconde mérite également que l’on s’y arrête. Elle consiste à induire des observations réalisées sur un échantillon aléatoire afin d’obtenir l'estimation de paramètres sur une population globale. Les estimations sont soit ponctuelles (utilisation d’estimateurs), soit des plages de valeurs (qui de toute façon s’établissent à partir des estimateurs) associées à une probabilité de se tromper pour cause d'échantillon non représentatif.
Remarque : si le niveau de cette page est plus élevé que vos attentes, vous pouvez bifurquer sur l'initiation aux intervalles de confiance et les exercices d'initiation (extraits d'épreuves de bac STMG et ES). Ces deux pages avaient été rédigées à une époque où les intervalles de confiance étaient au programme de terminale.
Procédure
Le statisticien estime un paramètre \(\theta\) d’une population, par exemple sa moyenne, sa proportion ou sa variance, à partir d'un estimateur issu d'une statistique d'échantillon. Un intervalle de confiance est construit autour de cet estimateur, qui est une variable aléatoire pour la bonne raison que si l'échantillon avait été différent, le paramètre l'aurait été également. Ce « périmètre de sécurité » n’est donc pas construit autour du vrai paramètre à estimer puisqu’il est inconnu. L’intervalle est lui-même aléatoire. Il est plus ou moins étendu selon la probabilité que l'on s'est donnée d'atteindre la cible. Ses bornes sont les limites de confiance.

Interprétation
Par conséquent, si l’on dit « la vraie moyenne a 95 chances sur 100 de se trouver dans cet intervalle », on prend le problème à l’envers. C’est comme si l’on considérait la vraie moyenne comme une variable aléatoire et notre intervalle comme LE standard. En revanche, il est de bon ton de dire « la probabilité pour que cet intervalle inclue la moyenne de la population est égale à 0,95 ».
Niveau de confiance
Cette probabilité est appelée niveau de confiance, ou coefficient de confiance. C’est la probabilité de réussite associée à notre estimation. Si on la note \(η\) (êta) et que l’on nomme \(α\) (alpha) la probabilité de commettre une erreur de première espèce (niveau de signification), nous avons \(1 – η = α.\)
\(α\) est généralement choisi à 0,05 ou 0,01. Ces seuils sont parfois fixés par des textes réglementaires mais ils sont souvent le fait d’une habitude…
L'illustration ci-dessous montre des intervalles de confiance issus de dix échantillons. Seul l'un d'eux, en rouge, ne contient pas la vraie valeur \(\theta .\) Mais nous ne pouvons pas le savoir puisqu'elle est inconnue. En revanche, nous voyons que si l'on acceptait des intervalles plus grands, ils contiendraient tous \(\theta .\) C'est un travail d'équilibriste ! Pour obtenir un niveau de confiance très élevé, il faut accepter des intervalles qui peuvent devenir si larges qu'ils n'offrent aucun intérêt : si l'on affirme qu'on a une probabilité de 1 que la moyenne des notes d'une classe se situe entre 0 et 20, on n'est pas plus avancé...
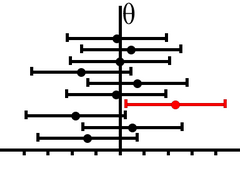
L’intervalle de confiance est asymptotique, c’est-à-dire que plus l’échantillon est grand, plus l’intervalle se resserre. Il suffit d’ailleurs d’un minimum de bon sens pour le deviner.
Enfin, on a raisonné sur l’erreur relative (précision de \(x\%\)) mais on peut aussi travailler sur un intervalle absolu. On cherche alors la taille de l’échantillon qui permet à tel intervalle d’inclure le paramètre à estimer pour une probabilité donnée.
Problème inverse, si l'on connaît les vrais paramètres d’une population mère et que l’on cherche sur un échantillon l’intervalle pour lequel on a 95 chances sur 100 que ce vrai paramètre s’y situe (ça arrive…), on parle d’intervalle de fluctuation ou de pari. Il est construit autour de la vraie valeur. On n’emploie pas d’estimateur et malgré de fortes similitudes il ne s'agit pas de statistique inférentielle (voir un exemple en page de loi hypergéométrique).
Tests
C’est dans le cadre des tests que les intervalles de confiance sont souvent, mais pas exclusivement, utilisés. Voir notamment la détection d'outliers par intervalle de confiance.
Les tests dits « paramétriques » utilisent des valeurs issues de lois statistiques, notamment la loi normale. Ils supposent qu’un travail préalable a été effectué pour s’assurer que la distribution observée est proche de celle d’une densité de probabilité connue.
Formules
Un intervalle de confiance calculé à la main nécessite soit les tables des différentes lois utilisées, soit des abaques. N’importe quel logiciel de statistiques vous restituant les intervalles des tests les plus courants, on réserve les vieilles méthodes aux amateurs de sport cérébral qui cherchent autre chose que le sudoku pour se détendre. Toutefois, au cas où vous auriez besoin d’en calculer un sur un coin de table, voici quelques formules.
Les exemples d’intervalles de confiance qui suivent sont bilatéraux. Les intervalles unilatéraux s’en déduisent facilement.
Proportion. Les limites de l'intervalle sont :
\[p \pm {t_{1 - \alpha / 2}}\sqrt {\frac{{p(1 - p)}}{n}} \]
Avec pour un seuil de 0,05 : \(t_{1 - \alpha / 2} = 1,96.\)
Moyenne (échantillon d’au moins 30 individus) :
\[m \pm t_{1 - \alpha /2} \frac{\sigma}{\sqrt{n}}\]
Avec pour un seuil de 0,05 : \(t_{1 - \alpha / 2} = 1,96.\)
Moyenne (échantillon de moins de 30 individus) :
La formule est la même mais il ne faut pas oublier d’utiliser l’écart-type sans biais. De plus, ça se complique un peu car il n’y a pas qu’une valeur de \(t\) au seuil 0,05. Il faut la trouver dans la table du \(t\) (pour test bilatéral) si votre logiciel ne se débrouille pas seul : colonne 0,05 et ligne \(n - 1.\) La valeur \(s’\) est l'écart-type sans biais. En fait, votre logiciel peut utiliser la table du \(t\) pour des échantillons beaucoup plus importants que 30. En effet, la valeur trouvée pour 29 degrés de liberté est de 2,045, ce qui n’est pas tout à fait la même chose que 1,96… Concrètement, \(t\) est toujours compris entre 2 et 3 si le test est bilatéral au seuil de \(5\%,\) sauf si l’échantillon est soit très grand soit minuscule (quatre observations ou moins).
Régressions
Les paramètres d'une régression simple ou multiple sont eux aussi des variables aléatoires et se trouvent au centre d'intervalles de confiance. Leur combinaison se traduit, pour la régression prise dans son ensemble, par un intervalle de prévision (ou de prédiction) dont la représentation graphique est composée de deux branches d'hyperboles autour d'une droite.
