Le test du \(F\) (de Fisher-Snedecor)
Vous disposez de deux échantillons indépendants et distribués normalement, et vous souhaitez savoir si leurs variances peuvent être considérées comme identiques, pour un niveau de confiance donné. Un test s'impose.
Utilités
Et d'abord, pourquoi se poser une question pareille ? Souvent, pour valider l’hypothèse de leur égalité (appelée homoscédasticité), condition sine qua non de l’utilisation du test du \(t\) (comparaison de moyennes). D'ailleurs, l'utilisation couplée de ces deux tests permet de valider l'inclusion de deux échantillons à une même population (le test du \(F\) pour les variances puis celui du \(t\) pour les espérances). Voir à cet égard la page comparaison de deux populations.

Cette recherche d'égalité constitue aussi la problématique de l’ANOVA (égalité d’une variance intra-classe et d’une variance interclasse) et de la corrélation (comparaison d'une variance expliquée par une régression avec une variance résiduelle à l'aide du coefficient de détermination). Dans le cadre d’un scoring qui discrimine deux groupes, le test de Fisher-Snedecor est réalisé sur chaque variable numérique pour vérifier l’hypothèse d’homoscédasticité : c’est l’une des conditions d’utilisation de l’analyse discriminante linéaire. Le test de variance, décidément utile à tous, sert aussi au prévisionniste pour détecter une saisonnalité et, dans le même temps, l'existence d'une tendance.
Il arrive cependant que le test de variance fournisse directement des conclusions : comparaison de répartitions salariales, de volatilité sur les marchés financiers, de rendements agricoles… Un choix privilégiant le moindre risque peut alors être argumenté par une variance plus faible. Mais c’est surtout dans le domaine industriel et particulièrement dans les contrôles de qualité que ce test est utilisé. Une machine bien réglée fabrique des produits dont les mesures présentent une variance plus faible que s’ils étaient usinés par une machine trop vieille ou mal réglée.
Théorie
Quand elles résument la dispersion d’échantillons et non d’une population totale, nos variances sont des variables aléatoires (v.a). On peut tomber sur un échantillon très dispersé ou au contraire sur un échantillon plus homogène. La différence observée entre les deux peut provenir de fluctuations d’échantillonnage, sauf si les variances sont trop dissemblables. Mais le risque d’erreur subsiste toujours. On va donc déterminer cette frontière entre semblable et dissemblable, en fonction d’un niveau de confiance donné.
Le test de variance permet d'estimer si ces variances peuvent être considérées ou non comme identiques. Grâce à quelle statistique ?
On sait qu’une somme de \(n\) v.a indépendantes suivant chacune la loi normale centrée réduite, élevées au carré, suit une loi du khi² à \(n\) degrés de liberté (enfin, c'est un rappel au cas où…). Passons les détails mais une somme de carrés d’écarts à une moyenne observée (variables centrées au carré) divisée par une vraie variance, suit une loi du \(\chi ^2.\)
Si \(S^2\) est l’estimateur de la variance, on a donc cette importante propriété :
\[\frac{(n - 1)S^2}{\sigma ^2} \leadsto \chi_{n-1}^2\]
Note : on multiplie \(S^2\) par \(n - 1\) et non par \(n\) pour que l’estimateur soit sans biais. En revanche, si l'on connaît la vraie moyenne, on multiplie bien par \(n.\)
Le rapport des variances estimées de deux échantillons (la plus forte étant au numérateur) suit une loi de Fisher-Snedecor puisque cette loi est celle du rapport entre deux v.a indépendantes qui suivent chacune une loi du \(\chi^2.\)
Revenons au test. Sous H0, les deux variances sont identiques. C’est donc un simple rapport de deux variances estimées qui suit une loi de Fisher-Snedecor de statistique \(F(n_1 - 1 \,; n_2 - 1).\) Ni les espérances, ni les vraies variances n’interviennent.
Le test du \(F\) avec Excel
H0 : les variances sont identiques.
H1 : les variances sont différentes (le rapport ne suit pas la loi de Fisher-Snedecor).
Le test du \(F\) est très facile à mettre en œuvre. Même le tableur gratuit d’OpenOffice vous donne directement la p-value. Avec Excel, on regrette une quasi-absence de mode d’emploi alors que l’illogisme règne : la fonction TEST.F donne la p-value d’un test bilatéral et l’utilitaire d’analyse fournit les résultats d’un test unilatéral…
On se passe d’ailleurs très bien de cet utilitaire qui n’apporte qu’un gain de quelques secondes et un risque de se tromper (vérifiez que c’est bien la variance la plus élevée qui était au numérateur car il n’y a pas de correction automatique). Quant au test unilatéral, il ne présente que peu d’intérêt…
Alors comment procéder avec Excel ? Le plus simple reste la fonction TEST.F. L’ordre dans lequel on entre les deux matrices n’a pas d’importance. On obtient une p-value que l’on compare avec 0,05 (ou tout autre seuil). Si elle est supérieure, on ne rejette pas H0. En cas de variances parfaitement égales, TEST.F donne 1 ; en revanche, plus les variances sont dissemblables, plus la p-value tend vers zéro.
Voici par exemple un tableau reprenant des âges et, dans le champ de l’étude préparatoire à une AFD, on cherche à savoir si la dispersion dans le groupe 1 est la même que celle observée dans le groupe 2.
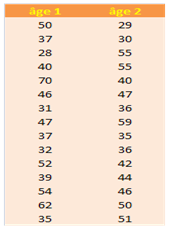
La fonction TEST.F restitue 0,359854. C’est une p-value supérieure à 0,05 et, si l’on s’était fixé ce seuil, on ne rejette pas l’hypothèse d’égalité des variances. Pourtant, l’une est égale à 143 et l’autre à 86,7 ! On touche ici à la crédibilité des analyses bâties sur de petits échantillons…
Si vous travaillez avec les tables, calculez le rapport des deux variances sans biais et comparez le résultat avec la valeur donnée par une table de Fisher (degrés de liberté du numérateur en colonnes. Piège : ce n’est pas nécessairement l’échantillon qui a le nombre de degrés de liberté le plus élevé qui a la plus forte variance).
Mais encore…
La comparaison de variances est également réalisée à l’aide de deux tests moins connus, celui de Levenne et celui de Bartlett.
Un exemple, dont est extrait le tableau ci-dessus et réalisé avec XLSTAT, figure en page de sélection de variables discriminantes.
Un calcul du \(F\) est décortiqué en page de tableau de l’ANOVA.
