Test sur moyennes de 2 petits échantillons
« Peut-on considérer, pour un risque d’erreur donné, que les moyennes de deux échantillons sont identiques ? » Si vous vous posez cette question, le test du \(t\) est fait pour vous.
Il s’agit d’un test qui peut également répondre à d’autres interrogations assez proches. Notamment : « la moyenne observée sur cet échantillon est-elle différente du montant envisagé a priori ? » (voir conformité d’une moyenne à une norme), ou encore « la moyenne de l’échantillon a évolué entre les périodes \(t\) et \(t + 1\) : peut-on considérer cette évolution comme significative ou comme étant un effet dû au hasard ? » (voir comparaison de moyennes sur deux échantillons appariés).

Cadre d'analyse
Dire que 38 et 40 sont deux moyennes considérées comme identiques n’a pas de sens si l’on ignore la taille de l'échantillon ou si l’on occulte la dispersion qui existe autour de ces valeurs. Celle-ci peut être forte s’il s’agit d’âges (et on considère qu’il n’y a pas grande différence entre 38 et 40 ans) mais faible s’il s’agit de températures corporelles (auquel cas on estime que la différence est importante).
Comme les moyennes sont mesurées sur un ou deux échantillons aléatoires, elles sont elles-mêmes des variables aléatoires (v.a). Le but de la manœuvre est de savoir si un écart entre deux moyennes (v.a lui aussi) est dû à une simple fluctuation d’échantillonnage ou si l’on admet l'existence d'une réelle différence, avec une probabilité de se tromper définie à l’avance. Cette probabilité est souvent de \(5\%\) (par défaut sur la plupart des logiciels).
Les deux échantillons doivent avoir des variances proches et être distribués de façon normale. Il est donc prudent d’intégrer en début de traitement les tests du \(F\) et les tests de normalité. En cas d’hétéroscédasticité, on se rabat sur d’autres tests (Satterhwaite et Cochran-Cox) ou sur version asymptotique du test \(t.\) Par ailleurs, lorsque l'effectif de chaque échantillon dépasse une trentaine, on préfère utiliser une approximation par la loi normale, plus pratique que le test du \(t\) et sans gros risque supplémentaire de se tromper (voir test \(z\)).
Enfin, il s’agit d’échantillons indépendants mais pas nécessairement de même taille.
Statistique
La statistique construite pour l’occasion est donc la différence entre les deux moyennes, réduite en la divisant par un écart-type estimé global. Elle suit un \(t\) de Student dont le nombre de degrés de liberté est égal à la taille de l’effectif global moins deux :
\[\frac{\overline{x}_2 - \overline{x}_1}{\sqrt{S^2 \left(\frac{1}{n_1} + \frac{1}{n_2} \right)}} \leadsto t_{(n_1 + n_2 - 2)}\]
Vous l’avez deviné, \(S^2\) est l’estimateur de la variance commune aux deux échantillons (on suppose la vraie variance inconnue, ce qui est le cas dans la quasi-totalité des situations) :
\[S^2 = \frac{1}{n_1 + n_2 - 2} \left[ \sum\limits_{i = 0}^{n_1} { \left(x_{1i} - \overline {x} _1 \right)^2} + \sum\limits_{j = 0}^{n_2} { \left(x_{2j} - \overline {x} _2)^2 \right)} \right]\]
Exemple
Un exemple : peut-on considérer que la moyenne des rémunérations dans les deux services suivants est identique ? Hypothèse 0 : elles sont identiques, avec un risque d'erreur de \(5\%.\) Hypothèse 1 : elles sont différentes.
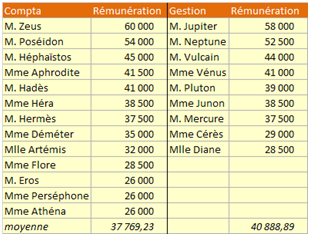
SPSS vient à notre rescousse.
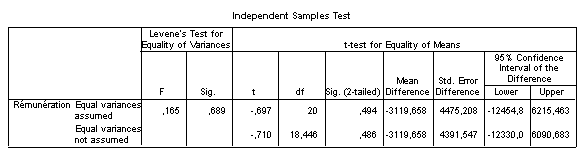
On considère ici que les moyennes sont proches et on retient H0. Sur la première ligne, on remarque que la p-value est de presque \(50\%.\) D’une manière générale, il faut d’énormes différences pour qu’un test admette des moyennes dissemblables sur d’aussi petits échantillons… On vérifie que l'écart entre moyennes (-3 119,658) se trouve bien dans la région d’acceptation \(]-12\,454,779 \,; 6\,215,463[.\)
Si l'on examinait trois échantillons ou plus, on procéderait à une ANOVA plutôt que de les tester deux à deux. Le traitement serait un peu différent : sur notre exemple, on considérerait alors un seul échantillon dont l'effectif est de 22 avec deux variables, dont une qualitative (compta vs gestion).
Lorsque les échantillons sont appariés, le mécanisme est le même mais les résultats sont très différents (voir exemple) car la région d'acceptation est beaucoup plus serrée.
Un exemple avec utilisation de XLSTAT figure en page de tests préalables à une analyse discriminante.
