Exemple de sélection de variable discriminante
Bien qu’une AFD ou une analyse discriminante décisionnelle peuvent se contenter d’hypothèses de normalité et d’homoscédasticité pas tout à fait satisfaites, il est plus sûr de vérifier qu’une méthode non linéaire n’est pas préférable… Les étapes illustrées sur cette page illustrent le processus décrit en page sélection de variables pour une analyse discriminante.
Exemple de tests de normalité
Ceci est le détail du traitement de la variable km / an, extraite de l’exemple de la page AFD.
Dans le cadre d’une étude de marché pour un constructeur automobile, un échantillon de trente automobilistes possédant un modèle particulier est interrogé. Celui-ci est séparé en deux groupes égaux : ceux qui changeront probablement de véhicule dans les deux ans à venir et ceux qui ne comptent pas le faire.
Variable à expliquer : 1 = pas de changement prévu. 2 = changement prévu.
| km/an | Âge | Taille foyer | Budget | Âge voiture | Change-ment ? |
| 3 000 | 50 | 2 | 4 00 | 5 | 1 |
| 7 000 | 37 | 1 | 1 000 | 3 | 1 |
| 8 000 | 28 | 4 | 1 200 | 3 | 1 |
| 10 000 | 40 | 3 | 2 000 | 2 | 1 |
| 13 000 | 70 | 2 | 3 100 | 1 | 1 |
| 15 000 | 46 | 5 | 3 000 | 2 | 1 |
| 20 000 | 31 | 4 | 2 500 | 3 | 1 |
| 20 000 | 47 | 3 | 2 800 | 2 | 1 |
| 25 000 | 37 | 2 | 2 500 | 1 | 1 |
| 25 000 | 32 | 2 | 3 500 | 2 | 1 |
| 28 000 | 52 | 3 | 3 000 | 1 | 1 |
| 30 000 | 39 | 3 | 4 000 | 4 | 1 |
| 40 000 | 54 | 2 | 2 500 | 3 | 1 |
| 45 000 | 62 | 1 | 2 800 | 2 | 1 |
| 50 000 | 35 | 2 | 2 500 | 2 | 1 |
| 12 000 | 29 | 2 | 2 000 | 4 | 2 |
| 15 000 | 30 | 1 | 3 000 | 5 | 2 |
| 25 000 | 55 | 2 | 3 000 | 3 | 2 |
| 26 000 | 55 | 2 | 3 200 | 5 | 2 |
| 30 000 | 40 | 5 | 2 500 | 1 | 2 |
| 30 000 | 47 | 3 | 1 000 | 2 | 2 |
| 35 000 | 36 | 3 | 3 000 | 5 | 2 |
| 35 000 | 59 | 2 | 4 500 | 7 | 2 |
| 40 000 | 35 | 3 | 3 000 | 6 | 2 |
| 42 000 | 36 | 3 | 3 200 | 7 | 2 |
| 45 000 | 42 | 4 | 2 800 | 4 | 2 |
| 50 000 | 44 | 4 | 3 600 | 4 | 2 |
| 60 000 | 46 | 2 | 2 400 | 3 | 2 |
| 60 000 | 50 | 3 | 4 000 | 4 | 2 |
| 80 000 | 51 | 2 | 5 000 | 4 | 2 |
Nous avons deux modalités de variable à expliquer et cinq explicatives soit dix distributions à tester mais on ne s’intéressera ici qu’à la variable km / an.
Réalisation sur XLSTAT (extrait) :
Ne sont repris ici que les tests de la première distribution (km / an si aucun changement prévu, soit \(n = 15\). Cliquer sur « Description des données ».
\(H_0\) : distributions normales. \(H_1\) : distributions un peu trop fantaisistes.

C’est OK. On ne rejette pas l’hypothèse de normalité au seuil de signification 0,05. Voyons si les autres tests confortent cette décision.



Toutes les p-values sont supérieures à 0,05. Ceci ne permet pas d’affirmer haut et fort que la distribution est normale mais, au moins, on peut poursuivre l’analyse…
Exemple de test du F
Peut-on considérer que, sur la variable km / an, les variances sont égales au seuil de 0,05 entre les groupes « changement » et « non changement » ?
Test de comparaison de variances : \(H_0,\) variances identiques. \(H_1\), variances différentes.
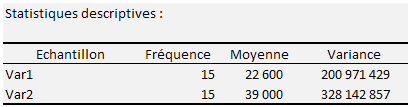
Après un premier tableau de statistiques descriptives, XLSTAT donne les résultats suivants :
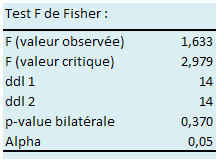
Joie ! On peut supposer l’homoscédasticité entre les deux groupes et, sous réserve de la même vérification sur les autres variables, envisager une analyse discriminante !
Test de comparaison de moyennes
S’il s’avère que km / an figure parmi les « nominés », on ne peut pas pour autant affirmer que cette variable est discriminante. L’examen suivant est particulièrement important : le nombre moyen de km / an est-il suffisamment différent entre les automobilistes qui changeront de voiture et les autres ?
Hypothèses : \(H_0,\) les moyennes sont égales. \(H_1,\) elles sont différentes.
Extraits de XLSTAT (test non paramétrique puis test t).

On peut rejeter l’hypothèse nulle d’égalité des moyennes et prendre en compte cette variable dans l’analyse. Que du bonheur…
