Test des groupes de Swed et Eisenhart
Une des raretés de la collection. Un test peu usité, sur lequel la littérature est parcimonieuse et parfois contradictoire. Mais pourquoi un tel mystère ?
Cadre d'analyse
Vous êtes en présence d’une variable dichotomique sur un échantillon ordonné et vous souhaitez savoir si la variable et l’ordre sont liés ou si au contraire les tirages sont indépendants. Il ne s’agit donc pas de déterminer que, sur un grand nombre de tirages à pile ou face, vous obtiendrez le même nombre de piles que de faces, mais de savoir si les piles ont tendance à suivre d’autres piles et les faces à suivre d’autres faces (la « loi des séries », en langage courant). Inversement, une alternance parfaite de piles et de faces est tout aussi suspecte.
Ce test permet de détecter l’autocorrélation d’une série chronologique ou un biais dans une enquête. Dans le cas de la série chronologique, on transforme la valeur observée pour obtenir une variable dichotomique (au-dessus versus au-dessous de la médiane, ou de la tendance…).
Qu’est-ce qu’une séquence ?
Une séquence est une suite d’évènements identiques. À titre d’exemple, il y a 2 séquences dans \((1,1,1,1,0,0,0),\) il y en a 4 dans \((1,1,0,1,0,0,0)…\)
On appellera \(R\) le nombre de séquences.
Combinatoire
Sur de petits échantillons, qu’importe si, théoriquement, on a une chance sur deux d’obtenir 0 ou 1. On ne s’intéresse qu’au résultat observé et à toutes les manières possibles de réaliser la même proportion de 0 et de 1. En d’autres termes, le test nécessite le calcul d’une combinaison de \(p\) zéros pris parmi \(n\) évènements. Le test des séquences est donc une application pratique du calcul combinatoire.
Approximations
Sur de grands échantillons, on procède à une approximation par la loi normale (le test s’enorgueillit alors d’être paramétrique). Si l’effectif est d'au moins 50, l’espérance est de \(\frac{50 + 2}{2} = 26\) et la variance s’établit précisément à \(\frac{n - 1}{4} - \frac{1}{4(n - 1)},\) qu’on peut en l’occurrence arrondir à \(\frac{50 - 1}{4} = 12,25.\) Au risque d’erreur de \(5\,\%,\) on considère que la série est aléatoire dans la fourchette \(50 \pm 1,96 \sqrt{12,25}.\)
Dans le cas où les effectifs de 0 et de 1 ne sont pas les mêmes, les formules se compliquent. L’espérance est alors : \(\displaystyle{\frac{2n_1n_2}{n_1 + n_2} + 1}\)
Éternelle question de savoir en-deçà de quel effectif on considère qu’un échantillon est petit. En général, l’approximation par la loi normale est appliquée à partir de 30 observations. Pour le test des séquences, J.-P. Georgin et M. Gouet considèrent que chacun des deux sous-effectifs doit contenir au moins 20 valeurs (Statistiques avec Excel…, PUR 2005, chap. 9). Cet ouvrage traite le sujet de la façon la plus complète qui soit…
Nous n’entrerons pas dans les détails théoriques mais nous vous proposons quelques exemples réalisés sur XLSTAT, ce logiciel permettant de nombreuses possibilités pour réaliser des tests de séquences. Ci-dessous, l’hypothèse nulle H0 sera toujours celle d’une répartition aléatoire.
Exemples
Voyons d’abord un exemple trivial de données qualitatives. Soient 20 valeurs, tantôt 0, tantôt 1. On flaire bien sûr du non-aléatoire…
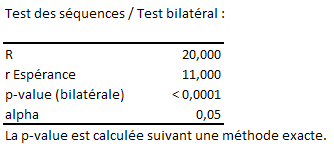
La p-value est presque nulle, ce qui nous amène bien sûr à rejeter H0.
Deuxième exemple, également trivial, avec données qualitatives : 20 zéros suivis de 20 uns (par exemple, 20 hommes puis 20 femmes qui répondent à une enquête).

Le rejet de H0 est encore sans appel, mais pour une raison évidemment inverse à celle de l’exemple précédent.
Troisième exemple. Prenons celui de la page régression sur tendance exponentielle. Soit l’évolution de la population de Montréal entre 1801 et 1931 (source : ville de Montréal). Le tableau ci-dessous donne les valeurs réelles, théoriques puis la différence entre les deux sur laquelle on testera \(R.\)
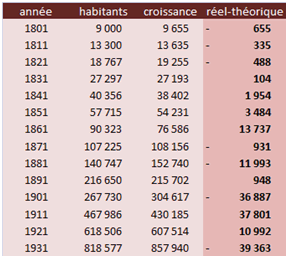

Si le modèle est correctement choisi, les valeurs observées sont réparties aléatoirement autour de la courbe d’ajustement. Le test des séquences précise alors l’impression visuelle donnée par le graphe. Si l’on avait bêtement opté pour un modèle de régression linéaire simple, la répartition n’aurait rien d’aléatoire (\(R\) serait alors égal à 3). Si \(R\) était au contraire trop élevé, on pourrait certainement améliorer notre modèle (la tendance serait effectivement exponentielle mais il faudrait peut-être prendre en compte une autocorrélation négative).
En tout cas, on constate sur cet exemple que la répartition est bien aléatoire. Nous vous présentons d’abord une analyse qualitative. \(R = 7,\) ce qui correspond au nombre de séquences positives et négatives.
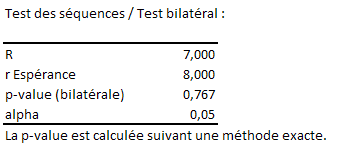
(...)
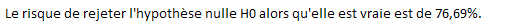
Ces résultats confortent donc la validité de notre régression.
On aurait pu opter pour une analyse quantitative, autour de la moyenne qui est de -1545. Vous pouvez vérifier facilement que \(R\) aurait alors été égal à 6. La p-value aurait été de 0,846. Autour de la médiane (-115), on aboutit sur cet exemple aux mêmes résultats qu’en choisissant l’analyse qualitative.
On voit donc que les applications de ce test sont de divers types, qualitatif ou quantitatif, fournissant un résultat opérationnel ou au contraire validant un choix méthodologique.
