Lissage exponentiel double (LED)
Le lissage exponentiel simple (LES) permet d’établir une prévision à \(t + 1\) lorsqu’il n’existe pas de tendance. Et lorsqu’il y en a une ? On double la dose. Et là, c'est bien connu, les LED nous éclairent...
Cadre d'analyse
Explcation. Si l’on souhaite établir une prévision par lissage sur une série chronologique avec tendance, il faut s’affranchir du principal défaut du LES qui est de prévoir la même valeur sur l'avenir quel que soit l'horizon. Ce type de prévision est évidemment inadapté lorsqu'on doit tenir compte d'une tendance !
D'où la technique du lissage exponentiel double (LED) qui exige la formalisation d'une tendance linéaire d'équation \(y = at + b.\) Graphiquement, l'extrapolation n'est plus horizontale mais poursuit une droite repésentative d'une fonction affine.
Celle-ci ne résume pas les valeurs d'une série chronologique de façon indifférenciée comme le fait une régression linéaire simple. Selon le principe du lissage exponentiel, les dernières observations pèsent davantage que les valeurs plus anciennes. La fonction de prévision est donc recalculée à chaque relevé supplémentaire. On dit qu'elle est localement linéaire. Une notation rigoureuse utilise des indices et un chapeautage de la variable estimée. Ici, \(h\) représente l'horizon de la prévision effectuée à l'instant \(t.\)
\(\hat{y}_t(h) = a_th + b_t\)
Précisons tout de même que si le LED autorise des prévisions plus éloignées que \(t + 1,\) le moindre écart sera amplifié à chaque recul de l’horizon de prévision. On demeure donc dans un contexte de court terme.

Mode d’emploi
Le LED nécessite un premier LES sur les données puis un second LES sur les valeurs qui viennent d'être déterminées. Il s'agit donc bien d'un double lissage.
À l’instar du LES, le LED repose sur le choix d’une constante de lissage alpha (\(α\)), comprise entre 0 et 1, qui permet de plus ou moins pondérer la dernière observation par rapport aux précédentes. Tout dépend évidemment de l'allure de la série chronologique à extrapoler mais intuitivement, on se doute qu’une petite valeur de \(α\) est souvent mieux adaptée. Un coefficient trop proche de 1 conduit en effet à des erreurs de prévision plus marquées qu'avec le LES.
Comment déterminer les paramètres d’une tendance localement linéaire ?
L’estimation de la « constante » \(b\) est égale à deux fois la première valeur lissée moins une fois la seconde valeur lissée.
Le coefficient directeur \(a\) est égal à la différence entre les deux valeurs lissées (la première moins la seconde), multipliée par un coefficient \(\frac{\alpha}{1 - \alpha}.\)
Ces paramètres sont déterminés à partir d’un principe bien connu en statistiques, celui de minimiser les carrés des erreurs (pondérés par leur « récence »).
Il reste un point à régler, celui de l'initialisation. Comme pour le LES, la première valeur peut être établie par le logiciel ou forcée par le prévisionniste (exemple ci-dessous).
Exemple
Un exemple réalisé avec Excel permet d’illustrer le LED. Les colonnes de lissage simple et double se calculent de la même façon. Les coefficients \(a\) et \(b\) évoluent avec le temps (soit deux relations de récurrence) et leur somme donne la prévision \(t + 1.\) Pour les horizons de prévision suivants, il suffit d’ajouter la dernière valeur de \(a\) à la prévision précédente.
Les lissages sont initialisés avec les deux premières valeurs observées. Les paramètres des fonctions affines sont initiés lors de la deuxième qui est \(b\) tandis que \(a\) est la différence entre celle-ci et la précédente.
Franchement, sur quel autre site le lissage exponentiel double est-il expliqué de façon si agréable ? On se croirait au CM2…
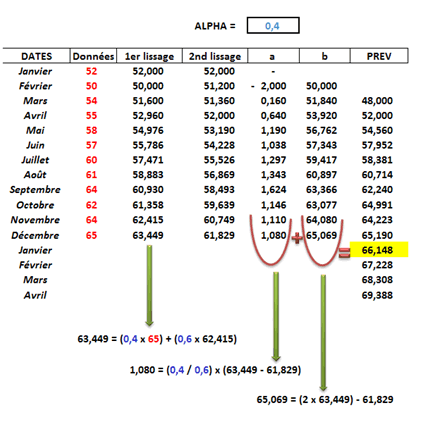
C'est la somme des paramètres de décembre qui fournit la prévision du mois suivant. Ensuite, il suffit d'ajouter pour chaque mois la valeur de \(a\) (1,08).
Un graphique permet de visualiser tout ceci (réalisé avec XLSTAT) :
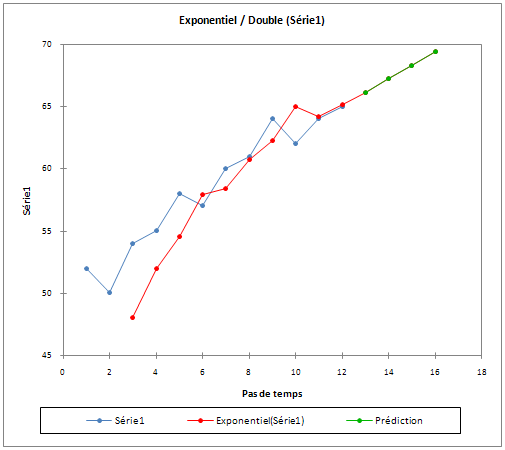
On perçoit bien les limites du LED, surtout pour les prévisions situées au-delà de \(t + 1.\) Non seulement elles dépendent fortement de la constante de lissage, mais elles peuvent beaucoup varier d’un mois sur l’autre (contrairement à une régression simple où le coefficient directeur reste constant). En pratique, on préfère souvent les lissages de Holt ou de Winters.
Une autre présentation du LED se trouve en page opérateurs de Box-Jenkins et un exemple supplémentaire est étudié en page d'exemple de lissages.
Bibliographie : méthodes de prévision à court terme, G. Mélard, SMA 2007 chap. 9, avec six présentations différentes du mécanisme du LED. Un excellent ouvrage qui n'est hélas plus édité.
