Lissage de Holt et exemple
Les méthodes de lissage exponentiel permettent de prolonger une série chronologique en vue de réaliser une prévision à court terme. On emploie le lissage exponentiel simple (LES) lorsqu’il n'existe aucune tendance. Mais bien souvent il en existe une, et ce sont le lissage double (LED) et surtout le lissage de Holt qui viennent à notre rescousse, voire le lissage de Winters s'il y a une saisonnalité.
Lissage de Holt et LED
Pour le prévisionniste, le lissage de Holt est une version améliorée du LED (on peut aussi considérer que le LED est un cas particulier du lissage de Holt).
Cette sophistication s’accompagne d’une connaissance en principe plus fine du sujet à traiter puisqu’il ne faut plus estimer UN paramètre \(\alpha\) (techniques du LES et du LED) mais DEUX : \(\alpha\) et \(\gamma\) (on peut les choisir empiriquement ou procéder à une optimisation).
Rappelons qu'avec le paramètre \(\alpha,\) on donne plus ou moins d'importance aux dernières réalisations par rapport à l'ensemble de la série.
Tout comme le LED, le lissage de Holt permet d’établir une fonction de prévision linéaire (en fait, fonction affine mais l'adjectif linéaire est habituellement employé en techniques prévisionnelles). Et si les formules ne peuvent plus être présentées de façon simplifiée, leur compréhension n’a rien d’insurmontable.
Pour un horizon \(h,\) une prévision établie à l'instant \(t\) s'écrit : \(\hat{y}_t(h)\) \(=\) \(a_t h + b_t.\)
Le niveau (à défaut d’un terme plus approprié…)
C’est une moyenne pondérée entre deux estimations de constante au moment de l'établissement de la prévision : d’une part celle qui est issue de la dernière observation, d’autre part celle qui avait été prévue. Le premier paramètre \(\alpha\) à choisir (compris entre 0 et 1) est donc celui qui va pondérer ces deux niveaux.
\(b_t\) \(=\) \(\alpha y_t + (1 - \alpha)(b_{t-1} + a_{t-1})\)
La pente
Là encore, on a une moyenne pondérée entre deux estimations, soit une deuxième relation de récurrence. On détermine un coefficient \(\gamma,\) compris entre 0 et 1, puis on applique cette pondération à la dernière estimation de pente observée, c’est-à-dire à la différence des deux niveaux en \(t\) et \(t - 1.\) Il nous reste \(1 - γ\) de pondération à appliquer. À qui ? À notre précédente estimation de pente, bien sûr...
\(a_t\) \(=\) \(\gamma (b_t - b_{t-1}) + (1 - \gamma)a_{t-1}\)
Avec un tableur
Nous cherchons à estimer le nombre de commandes reçues par une entreprise en janvier \(n + 1.\) Bien qu'inadaptées à ce cas concret, les décimales sont conservées afin que vous puissiez reproduire ces résultats si vous êtes motivé.
Les coefficients \(α\) et \(γ\) ont été choisis empiriquement, respectivement à 0,4 et 0,6. La série est initialisée à 0 pour la pente et à la première valeur (soit 220) pour le niveau.
| Mois | Commandes | b | a | Prévis. |
| Janvier | 220 | 220,00 | 0,00 | |
| Février | 224 | 221,60 | 0,96 | 220,00 |
| Mars | 226 | 223,94 | 1,79 | 222,56 |
| Avril | 225 | 225,43 | 1,61 | 225,72 |
| Mai | 230 | 228,23 | 2,32 | 227,05 |
| Juin | 232 | 231,13 | 2,67 | 230,55 |
| Juillet | 228 | 231,48 | 1,28 | 233,80 |
| Août | 232 | 232,45 | 1,10 | 232,76 |
| Septembre | 236 | 234,53 | 1,68 | 233,55 |
| Octobre | 236 | 236,13 | 1,63 | 236,21 |
| Novembre | 235 | 236,66 | 0,97 | 237,76 |
| Décembre | 239 | 238,18 | 1,30 | 237,63 |
| Janvier | 239,48 |
Les colonnes \(a\) et \(b\) ont été calculées à partir des formules ci-dessus. Ainsi, pour décembre :
\(238,18\) \(=\) \((0,4 × 239)\) \(+\) \((1 - 0,4) (236,66 + 0,97)\)
\(1,30\) \(=\) \(0,6 (238,18 - 236,66)\) \(+\) \(0,97 (1 - 0,6)\)
La prévision est la somme des valeurs \(a\) et \(b\) de la ligne précédente.

Choix des paramètres sur SPSS
En principe, on commence par choisir les valeurs des paramètres.
Si l’on opte pour un pas de 0,1 aussi bien pour \(α\) que pour \(γ\) nécessairement compris entre 0 et 1, nous avons le choix entre \(11^2 = 121\) possibilités. Sur une seule série, le calcul est rapide mais un double choix sur des milliers d’articles devient vite gourmand en traitement informatique. Une granulométrie moins fine (0,2 par exemple) s’avère alors nécessaire.
Pour revenir à notre exemple : sur SPSS, cliquer sur Time Series puis sur Exponential Smoothing…, sélectionner la série et choisir le modèle Holt. Cliquer sur Parameters… Sur le menu des paramètres, sélectionner Grid search aussi bien pour \(α\) que pour \(γ.\) On conserve les paramètres par défaut, à savoir 0,1 pour \(α\) et 0,2 pour \(γ.\) Dans Initial value, entrer la première valeur pour Starting, c’est-à-dire 220, et 0 pour Trend.
Résultat :
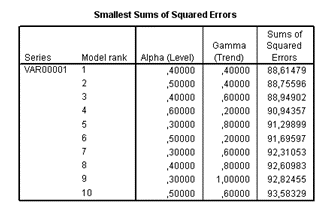
En se fondant sur le critère de la somme des carrés des erreurs, le meilleur modèle est celui qui retient une valeur de 0,4 pour \(α\) et pour \(γ.\) Reste à revoir la ou les prévisions avec ces paramètres…
Voir également l'exemple de lissages où le lissage de Holt est comparé à d'autres techniques (logiciel utilisé : XLSTAT).
