Test d'ajustement de Kolmogorov-Smirnov
Lui, c’est la clé à molette, l’outil non spécialisé qui s’adapte aux situations les plus variées. Et pourtant… Les logiciels n'en permettent souvent qu’une utilisation particulière, les exemples ne pullulent pas sur le web et la table n’est pas facile à trouver (voir tout de même Probabilités analyse de données et statistique de G. Saporta, technip 2011). Cerise sur le gâteau, si vous trouvez deux tables de sources différentes, elles risquent fort de montrer de petites différences.
Présentation
Le test de Kolmogorov-Smirnov (K-S) est l’un des tests d’adéquation non paramétriques les plus courants (avec le khi² mais ce dernier perd davantage d’information). Il porte le nom du mathématicien russe Andréi Nikoláyevich Kolmogorov qui établit l'axiomatique des probabilités en 1933.
Ce test permet d'estimer si le caractère d'un échantillon est distribué de façon comparable à celui d'un autre ou s'il peut être approximé par une loi de probabilité connue. Notamment, il donne une bonne indication d’ajustement à une loi normale (il est toutefois modifié dans ce cas précis et devient test de Lilliefors). De plus il s’adapte aux échelles ordinales, ce qui légitime son utilisation dans les études de marché. Son principal défaut est de ne pas être très efficace dans les queues de distribution.
Principe
Le principe est simple. On mesure l'écart maximum qui existe soit entre une fonction de répartition empirique (donc des fréquences cumulées) et une fonction de répartition théorique, soit entre deux fonctions de répartition empiriques.
Dans le premier cas, soit une fonction de répartition empirique \(F_n\) et la fonction de répartition d'une loi de probabilité théorique \(F.\)
\(d = \max |F_n(x) - F(x)|\)
Précisons que le test de K-S est indépendant de cette loi théorique : on peut comparer la répartition empirique aussi bien à une loi normale qu'à une loi de Poisson ou autre.
Dans le second cas, nous sommes en présence de deux échantillons \(A\) et \(B.\) Adaptons la notation :
\(d = \max |F_A(x) - F_B(x)|\)
Soit \(D\) la variable aléatoire qui prend la valeur de \(d.\)
Sous l’hypothèse H0, \(d\) tend vers 0. La distribution de \(D\) fait l'objet des tables de Kolmogorov, qui prennent en compte l’effectif de l'échantillon et le seuil de risque accepté : il suffit alors de comparer d à la valeur idoine de \(D\) dans la table.
Un graphe permet de visualiser ce qui est testé :
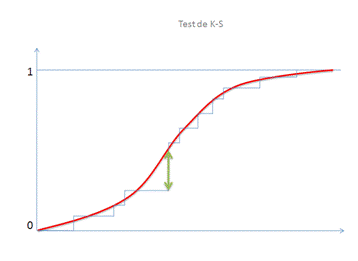
La flèche verte mesure l’écart maximum entre les valeurs observées (en bleu) et la fonction de répartition rouge considérée comme référente. C’est cette distance \(D\) qui est testée : compte tenu de l’effectif, la longueur de la flèche est-elle considérée comme « petite » ou « grande » ?
Exemple (adéquation à une loi)
Une nouvelle clientèle étrangère est attendue dans une station balnéaire. Afin de mieux connaître ses goûts, des brasseurs ont commandé une étude de marché. En début de saison, il est demandé à vingt de ces nouveaux touristes de donner leur préférence parmi cinq types de bières, de la moins amère (bière 1) à la plus amère (5). A l’aide d’un test de K-S, le chargé d’études décide de comparer les résultats avec une loi uniforme, c’est-à-dire une situation où chaque bière aurait la préférence de quatre répondants.

Les résultats de l’enquête sont les suivants :
1 3 2 5 1 2 2 4 1 2 2 1 3 3 2 4 5 1 1 2
On se fixe un risque d’erreur de \(5\,\%.\) L’hypothèse H0 à tester est celle de l’égalité avec une loi uniforme.
Étudions les écarts entre valeurs observées et répartition uniforme. Compte tenu des valeurs entières prises par la variable aléatoire et du faible effectif, la distribution observée a été comparée à une autre distribution en escaliers et non à une loi uniforme continue.
| Classe | Effectif | Unif. | Cumul réel | Cumul théorique | d |
|---|---|---|---|---|---|
| 1 | 6 | 4 | 0,30 | 0,20 | 0,10 |
| 2 | 7 | 4 | 0,65 | 0,40 | 0,25 |
| 3 | 3 | 4 | 0,80 | 0,60 | 0,20 |
| 4 | 2 | 4 | 0,90 | 0,80 | 0,10 |
| 5 | 2 | 4 | 1,00 | 1,00 | - |
La distance la plus élevée s’établit à 0,25.
Si l’on dispose d’une table, on lit pour \(n = 20\) et \(\alpha = 5\,\%\) une valeur de 0,294. On ne peut donc pas rejeter l’hypothèse selon laquelle les touristes n’ont pas de préférence particulière.
Pourtant un écart \(d\) de 0,25 point peut sembler énorme. Toujours selon la table, l'effectif de l'échantillon aurait dû être, pour une configuration identique d'amateurs de bière, d'au moins 28 individus pour que l'on rejette l'hypothèse d'égalité.
Voir un autre exemple d'utilisation avec les tests d'adéquation à un processus de Poisson.
