Test sur 2 moyennes (échantillons appariés)
Supposons. Vous êtes l’heureux observateur d’un échantillon dont vous relevez une moyenne. Illustrons ce propos par une flotte de véhicules dont vous constatez la consommation moyenne aux 100 km ou par un panel de consommateurs dont vous relevez la quantité mensuelle de dentifrice utilisée. Un an plus tard, vous mesurez à nouveau la consommation moyenne de votre panel et là, damned ! les chiffres sont différents… Cet écart est-il significatif et faut-il étudier le pourquoi du comment ou peut-on considérer qu’il ne provient que d’un petit aléa, voire d’une erreur de mesure ?
Échantillons appariés
L'appariement est une relation de dépendance entre des modalités. On relève des caractères d'un même échantillon plusieurs fois dans le temps. Ici, nous nous situons dans une situation simple où ce relevé n'a lieu que deux fois.
Les études d’échantillons appariés présentent souvent plus d’intérêt que les études sur échantillons indépendants. L’influence de facteurs exogènes est réduite et les résultats sont bien plus précis, donc plus opérationnels. L’hypothèse d’égalité des variances (test \(F\)) est inutile puisque ce sont les mêmes individus qui sont observés (consommateurs, patients, sujets d'une expérimentation de psychologie, etc.). Dans l'exemple qui suit, les fromages ont remplacé les humains (terrible perspective).
Exemple
Nous prévoyons une évolution des ventes de treize variétés de fromages. On relève la moyenne des différences pour la rapporter à son indicateur de dispersion (écart-type sans biais divisé par la racine carrée de l’effectif). La statistique obtenue suit une loi de Student à \(n - 1\) degrés de liberté.

Il s’agit d’un test de comparaison mais on peut le considérer comme un test de conformité à une norme puisqu’on compare une différence de moyennes à zéro, c’est-à-dire à un nombre.
En acceptant un taux d’erreur de \(5\,\%,\) les deux moyennes du tableau ci-dessous sont-elles différentes ?
| Fromage | Lundi | Mardi (prév.) |
| Mimolette | 34 | 24 |
| Comté | 56 | 55 |
| St-Marcellin | 78 | 76 |
| Gruyère | 90 | 82 |
| Roquefort | 121 | 100 |
| Brie | 165 | 154 |
| Ste-Maure | 188 | 170 |
| Camembert | 213 | 199 |
| Gouda | 200 | 180 |
| Bleu d'Auvergne | 160 | 155 |
| Emmental | 113 | 113 |
| St-Nectaire | 50 | 45 |
| Coulommiers | 2 | 0 |
| Moyenne | 113,077 | 104,077 |
On pose le test.
Hypothèse nulle (H0) : il n’y a pas d’évolution. H1 : il y a évolution.
On utilise ici XLSTAT, menu tests paramétriques puis Tests \(t\) et \(Z\) pour 2 échantillons (cochez « appariés »). Le résultat suivant apparaît (extrait) :
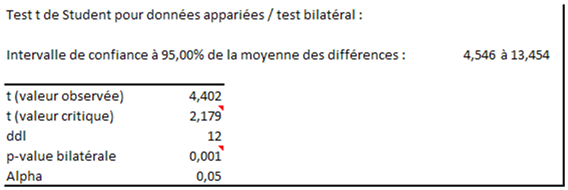
Décision : on rejette l’hypothèse H0. Pour le taux d’erreur que l’on s’est fixé, on considère qu’il y a évolution entre les ventes de lundi et les prévisions pour mardi.
Remarque : comme précisé, nous avons construit un test à partir de la moyenne des différences. Si par exemple on échange deux valeurs pour mardi (mimolette à 55 et comté à 24), le résultat sera bien sûr différent alors que si les échantillons étaient indépendants, ceci n’aurait aucune importance.
Extension
Maintenant, un peu de curiosité.
Supposons que nos deux échantillons soient indépendants (remplacez lundi et mardi par fromagerie d’Evry et fromagerie de Versailles). XLSTAT nous restitue ceci :
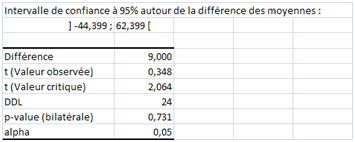
Avec deux fois plus de degrés de liberté, la p-value est largement au-dessus de 0,05. La valeur observée est inférieure à la valeur critique. Le test est beaucoup moins sévère. On considère maintenant que les deux moyennes sont identiques !
