Types de proximité des classifications
Cette page traite de la distance de proximité entre observations et non des différentes méthodes d’agrégation de la CAH.
Problématique
Dans un nuage de points, comment mesurer la distance entre un point et un autre ? Et sans placer une règle contre votre écran, ça ne fait pas sérieux…
1- La première idée : la distance euclidienne, base du théorème de Pythagore. Elle permet de mesurer l’inertie. C’est la distance habituellement retenue en classification hiérarchique et en typologie. L’inconvénient est le poids important des points se trouvant à une grande distance de l’origine de la mesure. Ceci ne les isole pas davantage, au contraire (Cf. exemple ci-dessous).
2- On peut aussi vouloir donner plus de poids aux valeurs aberrantes et choisir le carré de la distance euclidienne.
3- Autre possibilité, la distance de Manhattan (ou de Gower ou City block). Réservée aux classifications hiérarchiques, il s’agit de la somme des valeurs absolues des distances. Elle ne majore donc pas la pondération des outliers. En revanche, les temps de calcul sont particulièrement longs…
Illustration :
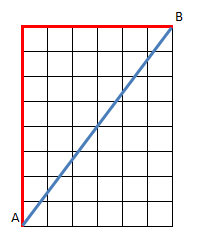
Dans cet espace à deux dimensions, les points \(A\) et \(B\) sont séparés de 6 unités sur une variable et de 8 unités sur une autre variable. La distance de Manhattan est donc de 14 (en rouge) tandis que la distance euclidienne est la racine carrée de \(6^2 + 8^2,\) soit 10 (en bleu). Manhattan est donc supérieure de \(40\,\%.\) Si les points étaient très éloignés, mettons de 20 et 40, Manhattan = 60 et Euclide = 44,7, soit une différence de \(34,16\,\%.\)

4- La distance de Tchebychev, elle aussi réservée aux classifications hiérarchiques. Alors que nous venons de voir des mesures de sommes, la distance de Tchebichev mesure la distance maximale qui existe entre deux points. Dans l’espace, un individu ayant UNE caractéristique extraordinaire sera plus isolé qu’un individu ayant plusieurs caractéristiques un peu particulières.
Il en existe plusieurs autres, parmi lesquelles le coefficient de Pearson (non repris dans l’exemple ci-dessous, les résultats obtenus me semblant particulièrement douteux en l’espèce) ; vous pouvez même paramétrer vos propres distances sur certains logiciels.
Exemple
Prenons maintenant l’exemple d’individus à classer en fonction de leurs réponses à une enquête (notes d'appréciation de 1 à 10). La méthode utilisée est la CAH et le cas est fictif. La faible quantité de données permettra de vérifier les résultats.
| Enquêté | Item 1 | Item 2 | Item 3 | Item 4 | Note |
| A | 5 | 6 | 8 | 9 | 28 |
| B | 5 | 7 | 8 | 8 | 28 |
| C | 9 | 8 | 4 | 4 | 25 |
| D | 9 | 7 | 4 | 5 | 25 |
| E | 9 | 8 | 4 | 4 | 25 |
| F | 4 | 3 | 9 | 3 | 19 |
| G | 4 | 3 | 8 | 4 | 19 |
| H | 4 | 3 | 9 | 4 | 20 |
| I | 5 | 5 | 6 | 9 | 25 |
| J | 4 | 5 | 5 | 9 | 23 |
| K | 7 | 5 | 6 | 9 | 27 |
| L | 5 | 5 | 5 | 9 | 24 |
| M | 5 | 5 | 4 | 9 | 23 |
| N | 1 | 2 | 2 | 2 | 7 |
| O | 2 | 2 | 2 | 1 | 7 |
On remarque 5 profils : A et B donnent des notes moyennes aux items 1 et 2 et élevées aux 3 et 4, C à E ont le profil inverse, F à H sont plutôt sévères sauf pour l’item 3, I à M notent moyen 1 à 3 mais attribuent 9 au dernier item, N et O n’aiment rien et, sur le critère de la note globale, ils se distinguent.
Les dendrogrammes ont été réalisés sur XLSTAT et la méthode d’agrégation est celle du lien moyen (plus adaptée à ce petit échantillon que le critère de Ward). Les valeurs sont comparables et ne sont donc ni centrées ni réduites.
En utilisant la distance euclidienne, XLSTAT propose trois clusters, d’extrême justesse car les individus C, D et E sont bien séparés des autres répondants de la même classe. Les outliers, pourtant bien à part, ne sont pas si isolés que ça...
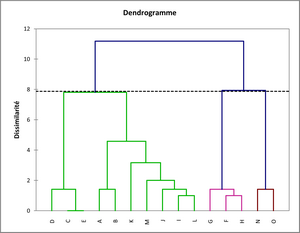
La distance de Manhattan semble plus conforme à notre lecture du tableau car les deux outliers sont bien séparés (isolés à un niveau élevé par le dendrogramme). Ensuite, ce sont les individus C, D et E qui sont considérés comme les plus différents et non F, G et H.
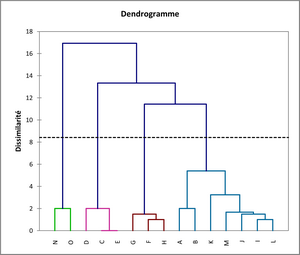
La distance de Tchebychev permet d’isoler davantage les deux outliers. En revanche, on considère que les individus F à H se distinguent mieux du lot que les répondants C à E, comme sur le premier dendrogramme. Il est vrai qu’ils présentent un profil plus tranché :
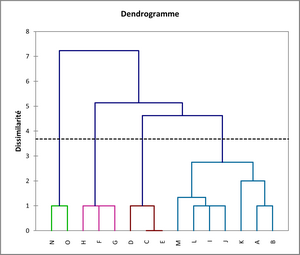
Sur cet exemple, c’est donc cette dernière distance qui semble être la plus conforme. Certes, une CAH requiert d’autres choix que la distance de proximité, notamment la méthode d’agrégation. Sur des échantillons importants, la distance euclidienne est le plus souvent utilisée en raison du temps de traitement et la littérature sur le sujet la privilégie. Ici, nous avons travaillé dans un espace à seulement quatre dimensions et nous voyons que les distances ne sont manifestement pas euclidiennes…
Dès qu’on peut utiliser plusieurs méthodes et les confronter aux avis d’experts, il faut l’accepter sans considérer pour autant qu’il s’agit d’une LIMITE du data mining.
