Agrégation des classes d'une CAH
Soit une population décrite par des variables quantitatives. Le défi à relever consiste à distinguer deux ou plusieurs sous-populations relativement homogènes. La classification ascendante hiérarchique (CAH) est une technique qui permet de réaliser un tel exploit. Mieux, elle permet de mesurer les proximités. Ainsi, les unités statistiques les plus proches sont d'abord regroupées, puis des sous-ensembles d'unités sont à leur tour considérés comme plus ou moins voisins les uns des autres. Le regroupement d'unités similaires (voire d'une seule) est nommé cluster.
Une classification ascendante
Ainsi, les distances sont utilisées afin d’établir une classification en arborescence. Celle-ci est ascendante puisqu'on procède à des regroupements. Si l'on partait de la population totale pour séparer des groupes dissemblables, la classification serait descendante.
Graphiquement, des observations comportant \(n\) variables constituent \(k\) sous-nuages de points aux contours en principe flous et aux formes pas toujours simples dans l'espace \(\mathbb{R}^n\).
Il existe plusieurs systèmes de mesure et telle technique efficace pour mesurer un éloignement entre deux formes de nuages laissera à désirer pour mesurer une distance entre deux autres formes. Heureusement (?), la panoplie des techniques est particulièrement large.

Méthodes
Neuf méthodes sont mentionnées ci-dessous.
- La méthode de Ward : c’est la plus courante. Elle consiste à réunir les deux clusters dont le regroupement fera le moins baisser l’inertie interclasse. C’est la distance de Ward qui est utilisée : la distance entre deux classes est celle de leurs barycentres au carré, pondérée par les effectifs des deux clusters. On suppose tout de même l’existence de distances euclidiennes entre observations. Cette technique tend à regrouper les petites classes entre elles.
- La distance minimale (single linkage) : elle est la plus simple à comprendre. Il s'agit de la plus petite distance mesurée entre deux observations de clusters différents. Elle produit souvent des nuages allongés.
- La distance maximale (complete linkage) : s’il n’y a pas d’outlier. Elle produit au contraire des nuages compacts (c’est-à-dire des cumulus alors que la distance minimale produit des cirrus ! Enfin, si cette image vous parle...).
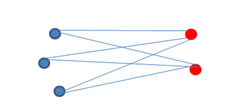
- La distance moyenne non pondérée (unweighted pair-group average linkage) : le logiciel mesure tous les liens entre chaque observation du cluster \(A\) et chaque observation du cluster \(B\) (dessin ci-dessous) et en fait une moyenne. C’est une des méthodes les plus efficaces. Elle tend à réunir des clusters aux inerties faibles : on voit bien que si les points bleus étaient davantage éloignés entre eux, la distance globale serait allongée….
- La distance moyenne pondérée (Weighted pair-group average linkage) : même méthode mais en pondérant chaque lien point à point en fonction du poids des clusters d’appartenance.
- La distance des barycentres non pondérée : assez simple, elle consiste à mesurer les distances entre barycentres de clusters.
- La distance des barycentres pondérée : idem, mais en pondérant par les poids des clusters, on évite des déséquilibres.
- La distance moyenne après fusion : moyenne de tous les liens, qu’ils soient entre observations de deux clusters différents ou intraclasses. Cette méthode est la seule qui s’attache directement au cluster obtenu et non aux caractéristiques des clusters candidats.
- Le bêta flexible : faites du tuning sur votre métrique ! Bêta est un coefficient paramétrable entre -1 et 1. \(\beta = 0\) équivaut à la méthode de la distance moyenne pondérée. Proche de 1 et les nuages s’allongent. Négatif et c’est l’inverse.
Les distances programmées sur XLSTAT font l’objet d’une comparaison sur ce site.
