Régression linéaire multiple avec variables binaires
Pas de théorie particulière sur cette page. Ce qui n’est pas une raison pour ne pas la lire… En effet, elle expose une technique assez simple pour modéliser une régression avec saisonnalité.
Cadre d'analyse
Pour simplifier, nous partons d’une régression linéaire simple opérée sur une chronique avec schéma de désaisonnalisation additif (ou multiplicatif complet transformé par les logarithmes), dans le louable dessein de prédire des valeurs futures.
Une technique un peu lourde consiste à désaisonnaliser, à réaliser une régression probablement annuelle sur la série temporelle exempte de mouvements saisonniers, puis à rajouter la saisonnalité afin d’effectuer une extrapolation. La technique concurrente que nous verrons ici consiste à utiliser une régression multiple qui intègre des variables dichotomiques (soit oui, soit non) indicatrices des « saisons ».
Si l’on travaille sur une série trimestrielle, ces variables seront au nombre de trois binaires. Il est inutile d’en retenir quatre puisque la régression sera effectuée sur un trimestre particulier, modifié ensuite pour déterminer toute valeur ne correspondant pas à ce trimestre (si l’on en utilisait quatre, leur moyenne serait nulle et il aurait colinéarité). En travaillant sur une série mensuelle, on dispose de onze variables saisonnières, et ainsi de suite si la périodicité est autre. L’équation du modèle diffère selon la période considérée comme étalon mais sa capacité prédictive n’en est pas affectée.
Comme ceci n’est qu’une application particulière de la régression multiple, illustrons-la sans plus attendre par un exemple réel. Précisons que celui-ci n’a qu’une valeur pédagogique, aucune hypothèse n’ayant préalablement été vérifiée (la tendance, notamment, n’est pas du tout affine).
Exemple : données
Étudions l'évolution de la récolte de maïs en France par trimestre (source INSEE). La variable « temps » représente la tendance (rang 1 au deuxième trimestre 2001), les trimestres 1, 2 et 3 apparaissent de façon disjonctive. La récolte est exprimée en milliers de tonnes.
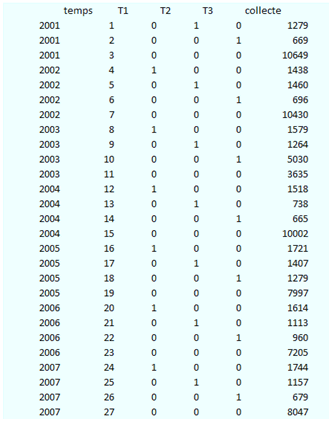

Régression
La régression multiple est ici réalisée sur SPSS. Le premier tableau ci-dessous montre que la corrélation obtenue SEMBLE très bonne, le \(R^2\) s’établissant à 0,831. Il pourrait s’agir d’un effet de tendance mais en l’espèce, celle-ci joue beaucoup moins que les mouvements saisonniers.
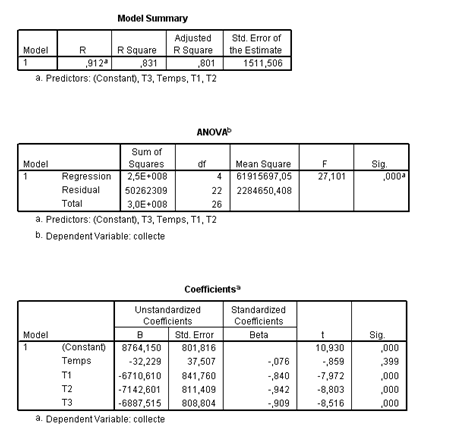
\[y = -32,23 \rm{Temps} - 6 710,6T1 - 7 142,6T2 - 6 887,5T3 + 8 764,2\]
Prévisions
Le premier trimestre 2008 a pour valeur temps 28. Nous pouvons prévoir une collecte de \((-32,23 \times 28) - 6 710,6 + 8 764,2\) =\(1151.\) Cette récolte fut en réalité de 1 804 milliers de tonnes…
Le deuxième trimestre 2009 a pour valeur temps 29. Cette fois-ci, la valeur « trimestre » à retenir est 7 142,6. La prévision s’établit à 687. Pour information, la récolte réelle a été de 1 725 milliers de tonnes.
Remarquez au passage la piètre validité du modèle, indiquée par le coefficient de détermination. En l’occurrence, ce n’est pas la tendance qui est en cause mais la très forte saisonnalité.
Terminons avec la prévision pour le quatrième trimestre 2009. Ici, y est tout simplement égal à \((-32,23 \times 31) + 8764,2\), soit 7 765 (en réalité 9 158).
Cet exemple présente une double vertu pédagogique : il détaille une technique de prévision mais il met aussi le doigt sur les limites de la régression utilisée comme méthode déterministe (dans notre cas, explication uniquement par le temps et non par les directives européennes ou par la météo…) et ceci malgré un coefficient de détermination trompeur dont il ne faut en aucun cas se satisfaire. Une autre méthode est très certainement préférable (lissage exponentiel de Winters, ARIMA…).
