Choix de la constante du lissage exponentiel simple
Le lissage exponentiel simple (LES) est une technique de prévision facile à mettre en œuvre. Ne nous réjouissons pas trop vite, la méthode comporte quelques écueils, notamment des conditions d’emploi assez restrictives (qui orientent alors l'analyse vers le lissage exponentiel double, le lissage de Holt ou autre) et du choix de la constante de lissage qui impacte directement les résultats.
En effet, aucune méthode mathématique ne donne directement la valeur optimale de cette constante. Réjouissons-nous à nouveau, après la lecture de cette page, vous saurez comment la choisir au mieux.
Principe
Pour cela, il faut évidemment conserver les données. Ainsi, on peut confronter les observations avec ce qu’aurait donné un LES utilisant une constante de lissage de 0,1 puis 0,2 puis 0,3 et ainsi de suite (en pratique, c’est un logiciel qui se charge de trouver la meilleure valeur !). On se donne un indicateur d’écart pour comparer les deux séries, par exemple l’erreur quadratique moyenne (MSE) ou l’erreur absolue moyenne (MAE) et donc déterminer la constante la plus adaptée à la série chronologique étudiée pour l'avenir.

Rappelons l’une des formules du LES :
\(\hat{y}_t = \alpha y_t + (1 - \alpha ) \hat{y}_{t-1}\)
Le coefficient \(α\) compris entre 0 et 1 pondère la dernière observation tandis que \(1 - α\) pondère la prévision précédente. Si l’on choisit \(α = 1,\) on reporte tout simplement la dernière donnée. Ainsi, une valeur élevée de \(α\) produit des prévisions très réactives tandis qu’une valeur faible implique un poids du passé plus fort et donc des prévisions davantage lissées.
On peut revenir sur le choix de la constante lorsque la série montre une rupture de tendance.
Explorons une série chronologique et quelques moyens d’obtenir la meilleure constante \(α.\)
Logiciels
Commençons par une technique artisanale avec Excel (comparaison de trois valeurs candidates de \(α\)) :
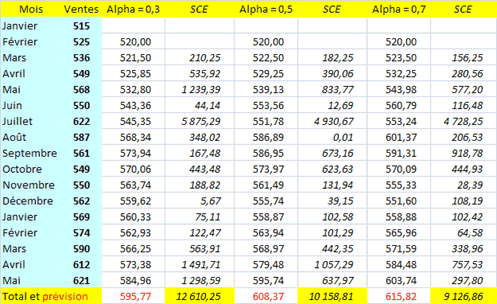
La valeur initiale choisie pour le lissage est la moyenne entre les deux premières observations. Les formules permettant d’obtenir les prévisions sont expliquées en page LES. Les colonnes SCE reprennent les différences entre les valeurs prédites et les observations de la colonne bleue, élevées au carré. On remarque que, des trois constantes étudiées, la plus adaptée est \(α = 0,7\) (somme des carrés des écarts la moins élevée).
Utilisons à présent XLSTAT-Time 2011, qui inclut un solveur et donc fournit une valeur de \(α\) bien plus précise que ci-dessus (500 itérations pour cet exemple).
La valeur \(S1\) qui initialise la série n’est pas la moyenne des deux premières. En effet, pour l’initialisation, XLSTAT autorise soit la première observation, soit la moyenne des six premières, soit un backcasting. Ce dernier consiste à faire un premier lissage à partir de la première valeur, puis à calculer des estimateurs et enfin à prendre ceux-ci comme valeurs initiales. Ici, nous nous contenterons de la première valeur (soit 515). Nous cherchons une valeur optimisée de la constante de lissage :
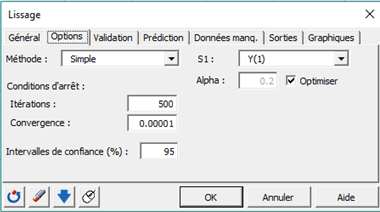
La validation n’est pas cochée dans l’onglet « Prédiction » et le pas de temps est 1. Voici un extrait de l’état de sortie :
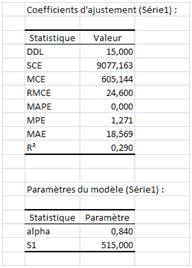
Un coefficient de 0,84 peut être retenu… On remarque que la SCE est logiquement inférieure à celle obtenue artisanalement avec \(α = 0,7.\)
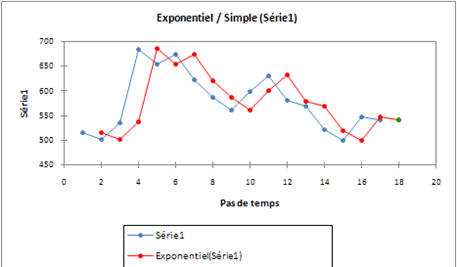
Pour terminer, voyons comment XLSTAT traite la série suivante (en bleu) en optimisant \(α\) :
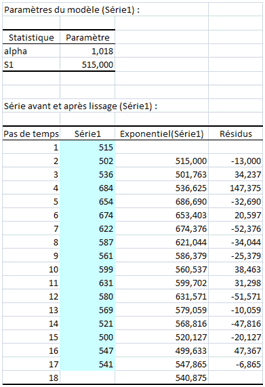
Un coefficient supérieur à 1… Cette sur-réaction est le signe d’une évolution très chaotique !