Échantillonnage stratifié
Sondage aléatoire, certes, mais avec une importante opération de chirurgie esthétique. Jugez-en.
Les strates
Un échantillonnage stratifié a priori suppose d'abord une connaissance de la population à étudier. Si l'on sait que celle-ci est hétérogène et regroupe plusieurs sous-populations bien distinctes, alors celles-ci seront représentées dans les strates de l'échantillon. Si elle est homogène, la stratification ne sert à rien.
On commence donc par la définition de \(H\) sous-ensembles homogènes (donc de faible dispersion), les strates. Elles sont choisies en fonction de leur corrélation avec les variables à étudier. Puis, pour chacune d'elles, on procède à un échantillonnage aléatoire simple.
Plusieurs niveaux de strates peuvent coexister. A titre d’exemple, un échantillonnage d’entreprises peut être opéré à partir d’une strate sur le type d’activité (code NAF) et d’une sous-strate sur leur taille. D'ailleurs l'INSEE utilise beaucoup la stratification dans ses enquêtes sur les entreprises, par nature très hétérogènes. Voici pour le principe.
Deux techniques
Deux options : soit on applique le même taux de sondage dans chaque strate (échantillon représentatif ou proportionnel), soit on optimise la taille de chaque sous-échantillon en le pondérant par les écarts-types. Cette deuxième technique, dite de Neyman, est particulièrement astucieuse s’il existe de fortes disparités intra-classes. Plus la dispersion est importante dans une strate, plus le taux de sondage y sera élevé. À défaut de connaître la variance, on utilise la somme de la variable considérée (les deux étant souvent bien corrélées).
Précision
L’intérêt de toutes ces péripéties, c’est que les sondages sur sous-ensembles homogènes sont plus précis qu’un sondage global, a fortiori lorsque les strates montrent de fortes disparités entre elles, comme on le verra sur un exemple. Si l’on estime une moyenne par stratification, sa variance sera plus faible que si elle est estimée à partir d’un échantillon aléatoire simple car on a moins de risque de sélectionner un échantillon non représentatif. Si c’est une proportion que l’on estime, les remarques sont les mêmes puisqu’on utilise alors une variable d’intérêt dichotomique traitée comme une moyenne.
Variances
Nommons \(h\) l’indice d’une strate et \(N_h\) la taille de la strate \(h.\) La moyenne \(m\) de la population totale \(N\) est bien sûr la somme des moyennes de strates pondérées par les poids de chaque strate.
\[m = \sum\limits_{i = 1}^H {\frac{{{N_h}}}{N}} {m_h}\]
Son estimateur sans biais \(\hat{m}\) est obtenu avec les moyennes observées.
La variance totale \(\sigma ^2\) est décomposable en intra et inter-strates (phénomène bien connu, voir les pages inertie, ANOVA, typologies, analyse factorielle discriminante...). Soit \(\sigma_h^2\) la variance d'une strate \(h\). La variance intra-strate est la suivante :
\[\sigma _W^2 = \sum\limits_{i = 1}^H {\frac{{{N_h}}}{N}} \sigma _h^2\]
Quant à la variance inter-strates...
\[\sigma _B^2 = \sum\limits_{i = 1}^H {\frac{{{N_h}}}{N}} {({m_h} - m)^2}\]
Et bien sûr \(\sigma^2 = \sigma_W^2 + \sigma_B^2.\)
Autre avantage et limites
D’autres atouts sont à prendre en compte comme la spécialisation éventuelle des enquêteurs.
Les limites de la technique apparaissent quand les critères de stratification sont mal maîtrisés et que des erreurs polluent le classement. Mais les résultats ne seront pas biaisés pour autant et pas moins fiables qu’avec un échantillonnage aléatoire simple, contrairement à ce que l’on obtiendrait avec des quotas mal définis. Par ailleurs, la sagesse recommande d’arbitrer entre le gain de précision et le coût éventuel d’une stratification super bien ficelée.
Exemple
Soit un audit social réalisé dans une banque parfaitement fictive. On souhaite interroger un échantillon représentatif de 200 salariés qui reflète la diversité des niveaux hiérarchiques. Ces niveaux sont liés à des coefficients. Toutes les directions doivent être représentées et c’est le critère d’appartenance à une direction qui servira de strate.
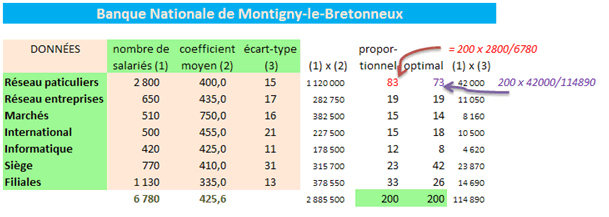
Vérifions le gain de précision sur notre exemple en calculant les trois variances de l’espérance. Pour cela, on a besoin de connaître la variance de l’échantillon. Dans la réalité, on l’obtiendrait en interrogeant la base de données mais ici on ne dispose que d’un tableau récapitulatif. On va néanmoins la retrouver grâce à sa décomposition, comme vu plus haut avec la formule de la variance de population, sauf qu’on lui applique la correction habituelle pour qu’elle soit sans biais.

Ce qui saute aux yeux, c’est que la quasi-totalité de la variance totale s’explique par les coefficients de la direction des marchés, très éloignés de ceux des autres directions. La variance intra-strate n’est jamais très forte, montrant une relative homogénéité au sein de chaque direction. Ainsi, il est logique que l’écart-type global soit bien plus élevé que n’importe quel écart-type intra-classe.
On cherche à diminuer la variance de \(\hat{m}\) en stratifiant le sondage.
Maintenant que nous disposons de tous les éléments, revenons à notre préoccupation de comparer les trois variances qu’il est possible d’obtenir.
Premièrement, sondage aléatoire simple.
Sans stratification, la variance d’un estimateur de moyenne se présente ainsi :
\[V(\hat{m}) = \left(\frac{N - n}{N - 1} \right) \frac{\sigma ^2}{n} \approx \left(1 - \frac{n}{N} \right) \frac{\sigma ^2}{n}\]
Soit \(\frac{6\,780 - 200}{6\,780 - 1} \times \frac{9\,973}{200} = 48,4\)
Deuxièmement, sondage stratifié proportionnel.
La formule exacte d’une variance d’échantillon stratifiée est la suivante :
\[V(\hat{m}) = \left( \frac{N_h}{N} \right) ^2 \left(\frac{N_h - n_h}{N_h - 1} \right) \frac{\sigma ^2}{n_h}\]
En l’appliquant, on trouve 1,53. Le gain de précision par rapport à 48,4 est énorme, ce qui est logique puisque l’essentiel de la variance globale est dû, comme nous l’avons vu, à une variance interclasses écrasante.
Troisièmement, sondage stratifié optimal.
Avec la même formule, on trouve 1,39. Il n’y a plus grand-chose à grappiller par rapport à la stratification précédente ! Mais cet exemple est un cas d’école, avec de faibles variances « within ». Toutes les populations ne présentent pas une configuration aussi particulière…
Note : pour la démarche de cet exemple, nous nous sommes inspirés de l’exercice donné par Daudin, Robin et Vuillet, « Statistique inférentielle. Idées, démarches, exemples » (PUR 2001) p. 25. Présentation et chiffres sont évidemment différents, et ce sont les formules exactes qui ont été utilisées, indiquées notamment par Bernard Grais (Méthodes statistiques, Dunod, 1983).
