Démonstrations sur estimateurs sans biais
Le type de modélisation le plus simple est celui qui résume une possible liaison entre deux caractères quantitatifs sous la forme d’une équation de droite. Cette dernière est établie à partir d’une régression linéaire simple (RLS). Ses paramètres sont des estimateurs puisqu’en général ils sont construits sur la base d’un échantillon. Ils sont au nombre de trois : le coefficient de régression, la constante et la variance des erreurs (que nous n’étudierons pas ici).
Soit le modèle suivant où \(x_i\) est la valeur prise par la variable aléatoire \(X\) pour la réalisation \(i\) (variable explicative). La valeur à expliquer \(Y\) est calculée grâce à deux paramètres estimés, le coefficient de régression \(a\) (coefficient directeur de la droite) et la constante \(b\) (ordonnée à l’origine) : \({\widehat y_i} = \widehat a{x_i} + \widehat b\)
Démontrons que ceux-ci sont sans biais, c’est-à-dire que leurs espérances sont égales aux vrais paramètres \(a\) et \(b.\)

Le coefficient de régression
Comment estimer \(\widehat {a}\), coefficient directeur de la droite des moindres carrés ?
Par définition, c’est le rapport entre la covariance entre \(x\) et \(y\) et la variance de \(x.\) Notons la variable à expliquer en majuscule, non pour vous embrouiller mais pour rappeler qu’il s’agit d’une variable aléatoire (pour simplifier l’écriture, nous n’indiquerons pas que les sommes s'appliquent à \(n\) termes).
\(\displaystyle{a = \frac{{\sum {\left( {{x_i} - \overline x } \right)\left( {{Y_i} - \overline Y } \right)} }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}}}}}\)
Factorisons pour obtenir une formulation plus simple à travailler.
\(\displaystyle{a = \frac{{\sum {\left( {{x_i} - \overline x } \right){Y_i} - \overline Y } \sum {\left( {{x_i} - \overline x } \right)} }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}}}}}\)
Comme la somme des \(n\) valeurs d’une série statistique est égale à \(n\) fois la moyenne, on peut écrire :
\(\displaystyle{\sum\limits_{i = 1}^n {\left( {{x_i} - \overline x } \right) = 0}}\)
Donc on peut donc exprimer \(a\) ainsi : \(a = \frac{{\sum {\left( {{x_i} - \overline x } \right){Y_i}} }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}} }}\)
Maintenant, quelle est l’espérance de \(\widehat{a}\) ?
\(\displaystyle{E(\widehat a) = E\left( {\frac{{\sum {\left( {{x_i} - \overline x } \right){Y_i}} }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}} }}} \right)}\)
Le calcul de l’espérance n’a de sens que pour une seule composante de cette expression : la variable aléatoire.
\(\displaystyle{E(\widehat a) = \frac{{\sum {\left[ {\left( {{x_i} - \overline x } \right)E({Y_i})} \right]} }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}}}}}\)
L’espérance d’une valeur de \(Y_i\) est donnée par l’équation de la droite de régression, comme illustré ci-dessous :
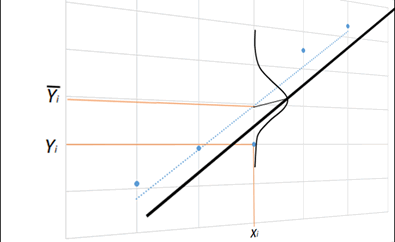
Mais comme nous devons utiliser l’équation sans paramètres estimés, il nous faut ajouter l’erreur \(\varepsilon_i.\)
\(\displaystyle{E(\widehat a) = \frac{{\sum {\left[ {\left( {{x_i} - \overline x } \right)E(a{x_i} + b + {\varepsilon _i})} \right]} }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}}}}}\)
Utilisons les propriétés de l’espérance.
\(\displaystyle{E(\widehat a) = \frac{{\sum {\left( {{x_i} - \overline x } \right)\left[ {aE({x_i}) + E(b) + E({\varepsilon _i})} \right]} }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}}}}}\)
Il va de soi que \(E(b) = b\) et par construction \(E(\varepsilon_i) =0.\)
\(\displaystyle{E(\widehat a) = \frac{{\sum {\left( {{x_i} - x} \right)\left[ {aE({x_i}) + b} \right]} }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}}}}}\)
\(\displaystyle{E(\widehat a) = \frac{{b\sum {\left( {{x_i} - \overline x } \right) + a\sum {\left( {{x_i} - \overline x } \right)E({x_i})} } }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}}}}}\)
Deux remarques : \(b\) multiplie 0 (comme vu plus haut) et \(x\) n’est pas une variable aléatoire (donc \(E(x_i) = x_i).\)
\(\displaystyle{E(\widehat a) = \frac{{a\sum {\left( {{x_i} - \overline x } \right)({x_i})} }}{{\sum {{{\left( {{x_i} - \overline x } \right)}^2}}}}}\)
Or, nous avons l’égalité suivante, démontrée en page de somme des carrés des écarts à la moyenne :
\(\displaystyle{\sum\limits_{i = 1}^n {{{\left( {{x_i} - \overline x } \right)}^2} = } \sum\limits_{i = 1}^n {\left( {{x_i} - \overline x } \right){x_i}}} \)
Ce qui simplifie considérablement notre quotient puisqu'il ne nous reste que \(E(\widehat{a}) = a.\) La démonstration est faite.
L’ordonnée à l’origine
Quelle est l’espérance de l’estimateur ?
\(E\left( {\widehat b} \right) = E\left( {\overline Y - \widehat a\overline x } \right)\)
\( \Leftrightarrow E\left( {\widehat b} \right) = E\left( {\overline Y } \right) - \overline x E\left( {\widehat a} \right)\)
Considérant la démonstration précédente, nous pouvons écrire :
\(E\left( {\widehat b} \right) = E\left( {\overline Y } \right) - a\overline x \)
\( \Leftrightarrow E\left( {\widehat b} \right) = \frac{1}{n}\sum {E\left( {{Y_i}} \right)} - a\overline x \)
\( \Leftrightarrow E\left( {\widehat b} \right) = \frac{1}{n}\sum {\left( {a{x_i} + b} \right)} - a\overline x \)
\( \Leftrightarrow E\left( {\widehat b} \right) = a\overline x + b - a\overline x \)
\( \Leftrightarrow E\left( {\widehat b} \right) = b\)
L’estimateur de \(b\) est sans biais.
