Skewness
Ah les statistiques ! Toujours des tas d’outils différents pour répondre à une même question. Déformation professionnelle des statisticiens, trop habitués à travailler l’incertitude ? Ou plus sérieusement, traduction d’une discipline qui évolue rapidement, utilisant les sciences exactes tout en les servant mais sans en être une ? Prenez l’asymétrie, par exemple. Graphiquement, il s’agit de l’étalement à gauche ou à droite de la représentation d'une série statistique ou d'une courbe représentative d'une densité de probabilité. On le mesure à l'aide d'un indicateur de forme, à l'instar du kurtosis. Eh bien il n’existe pas moins de quatre instruments pour la mesurer, sans parler ni des méthodes plus approximatives qui répondent juste à la question « gauche, droite ou symétrie », ni des variantes sans biais.
Méthodes empiriques
Ces méthodes dites approximatives sont l’observation du graphique et la position de la moyenne par rapport à la médiane.
Ainsi, à moins de présenter une configuration très cahotique, une distribution étalée à gauche présente la configuration suivante :
Mode > Médiane > Moyenne.
Et, miracle de la réversibilité, l’étalement à droite se traduit par l'ordre inverse.
Passons maintenant aux véritables outils de mesure.
Le coefficient d’asymétrie de Fisher (skewness)
Outil banal de la statistique, il s’agit du moment centré d’ordre 3 normalisé par le cube de l’écart-type, c’est-à-dire :
\(\displaystyle{\gamma_1 = \frac{1}{n\sigma^3} \sum_{i} (x_i - m)^3}\)
On le surnomme « gamma un ».
Comme c’est un nombre sans dimension, il permet de comparer des distributions même si leurs échelles diffèrent. Lorsque l’étalement est à gauche (moyenne en principe inférieure à la médiane), le coefficient d’asymétrie est négatif et vice versa.
Si vous utilisez habituellement la loi normale (ça dépend de votre domaine d’activité), vous ne vous intéressez probablement pas à ce coefficient puisque la fonction de densité de cette loi est symétrique (skewness = 0, comme vous l’avez deviné). En revanche, si vous travaillez sur des distributions toujours dissymétriques (répartitions salariales, VaR…), vous regardez peut-être de plus près ce « gamma un ».
Généralement, on observe le coefficient d’aplatissement (kurtosis) en même temps que celui d’asymétrie. D’ailleurs, parmi les différents tests d’adéquation à la loi normale, il s’en trouve un qui intègre ces deux paramètres : celui de Jarque-Bera.
Comment savoir si un skewness est compatible avec l’hypothèse de normalité ? Soit en utilisant un logiciel qui a la bonté de vous restituer un petit commentaire, soit en se reportant aux tables. Ces dernières ne se trouvent hélas pas partout. Voir par exemple « Probabilités, analyse des données et statistique » de G. Saporta (éd. Technip) p. 587. Les valeurs sont données pour des risques de \(1\,\%\) et de \(5\,\%\) pour \(n\) entre 7 à 5 000. À titre d’exemple, pour un échantillon de 1 000 unités statistiques et un risque d’erreur de \(5\,\%,\) le coefficient doit être compris entre -0,127 et 0,127 pour considérer que la distribution est bel et bien symétrique.
Une fonction de densité qui ne se rattache à aucune loi de probabilité mais qui conserve une forme « classique » (croissante puis décroissante) peut ainsi être définie par quatre moments : espérance, écart-type, asymétrie et aplatissement. C’est le cas des distributions de pertes de portefeuilles de crédit (VaR de crédit) ou de certains instruments financiers. L'asymétrie est la traduction d'un gain potentiel limité alors que les pertes sont rares mais parfois très sévères.
Avec Excel et le tableur d'OpenOffice, utilisez la fonction COEFFICIENT.ASYMETRIE. Mais attention, à l’instar de la variance, le coefficient d’asymétrie relevé sur un échantillon est biaisé pour estimer celui de la population ! C’est pourquoi les logiciels ne restituent pas le coefficient tel que nous vous l’avons présenté…
La formule est alors la suivante :
\(\displaystyle{\frac{n}{(n-1)(n-2)} \sum_{i} \left(\frac{x_i - 3}{\sigma} \right)^3}\)

Les coefficients d’asymétrie de Pearson
Il y en a deux. D’où certaines confusions…
L’un est le carré du coefficient de Fisher, donc toujours positif, l’autre est la différence entre moyenne et mode, divisée par l’écart-type.
Le coefficient d’asymétrie de Yule et Kendall (ou de Bowley)
On a juste besoin des quartiles pour le calculer. Il est de conception très simple mais bon, il fallait y penser…
\(u\) \(=\) \(\frac{(Q3-Q2)-(Q2-Q1)}{(Q3-Q2)+(Q2-Q1)}\)
Comme il n'existe pas de table, donc pas de critère précis de séparation entre symétrie et asymétrie, on utilisera plutôt ce coefficient comme élément de comparaison entre deux distributions.
Exemple
Belle illustration d’étalement à droite (asymétrie positive) :
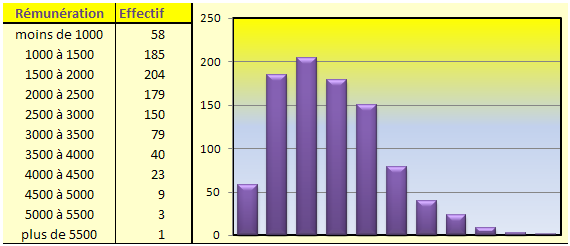
Pour établir les coefficients, nous avons arbitrairement recomposé cet échantillon de 931 salariés en attribuant les centres de classes de rémunération à l’effectif de chaque tranche (900 pour la première et 6 000 pour celui qui gagne bien sa vie). La fonction statistiques descriptives de XLSTAT 2014 contient trois coefficients : asymétries de Pearson, de Fisher et de Bowley. Respectivement 0,775, 0,777 et -0,333. Les deux premiers sont positifs comme on pouvait s’y attendre en remarquant l’étalement à droite sur le graphique. Après vérification, il s’avère que « l’asymétrie de Pearson » au sens de XLSTAT correspond en fait au coefficient de Fisher. « Asymétrie » cache la fonction COEFFICIENT.ASYMETRIE d’Excel, c’est-à-dire sans biais.
