Exemple de calcul pour régression multiple
Voici une page qui devrait davantage intéresser les étudiants que les statisticiens d’entreprise. Il faudrait vraiment que ces derniers soient démunis pour se lancer dans le calcul manuel d'une régression linéaire multiple ! Et encore, Excel sur lequel nous nous appuyons ici n’a rien de manuel… Mais vous êtes certainement curieux de connaître les mécanismes qui se cachent derrière les états fournis par les logiciels, n’est-ce pas ?
Données
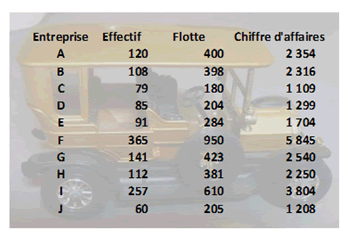
Illustrons. Nous connaissons dix entreprises de location de véhicules pour lesquelles nous souhaitons estimer le chiffre d’affaires (CA) à partir de deux critères que sont l’effectif de l’entreprise et son nombre de véhicules (flotte).
Problématique
Notre objectif est de prédire une variable aléatoire \(Y\) (le CA) à partir d’une variable \(x_1\) connue (l’effectif) et d’une variable \(x_2\) connue (la flotte). Le squelette du modèle apparaît : \(\widehat y\) \( = {\widehat a_{1}}{x_1} + {\widehat a_{2}}{x_2} + \widehat b + \varepsilon \)
Le travail du data analyst est de trouver les meilleurs paramètres \({\widehat a_{1}}\) et \({\widehat a_{2}}\) ainsi qu'un estimateur de la constante \(b.\) Si l’on se donne \(x_1\) (l’effectif) et \(x_2\) (la flotte), on déduira, si tout se passe bien, un CA convenablement exact…
Traitement
Transformons le tableau en deux matrices. La première est constituée des valeurs des deux variables explicatives ainsi que d’une colonne de 1 qui permettra l’existence de l’intercept \(b.\) La seconde est celle des \(y_i\), valeurs prises par la variable à expliquer.
Le calcul matriciel est effectué avec l’add-in d’Excel Matrix.

Si \(X’\) est la transposée de \(X\), la matrice des coefficients est \((X’X)^{-1}X’Y.\) Ouvrons le bal avec \(X’X\) :

La matrice inverse \((X’X)^{-1}\) est :

Quant à \(X’Y\), c’est une autre histoire…

Et voici que les destins se croisent pour nous offrir la matrice des coefficients \((X’X)^{-1}X’Y.\)

D’où l’équation \(\widehat y = 2,7811{x_1} + 5,0791{x_2} - 0,9\)
Vu les montants, la constante -0,9 est juste là pour faire joli… Estimons à présent la variance de l'erreur \(\sigma^2\) à partir des résidus de la régression.

La racine carrée s’établit à 15,425. Nous pouvons maintenant calculer les écarts-types des trois estimateurs. Soit \(\sigma^2(X’X)^{-1}\) :

Cette matrice des variances-covariances fournit les variances des estimateurs, donc leurs écarts-types (par ordre d’entrée en scène, donc d’abord la constante) :

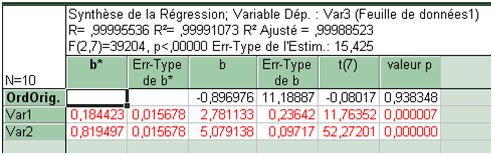
Voici ci-dessous la sortie d’un logiciel, en l’occurrence Statistica. La troisième et la quatrième colonne présentent les résultats établis ci-dessus. On retrouve également la valeur de l’erreur-type. La suite de l'analyse figure en page tests sur paramètres de régression, à l'exception des validations d'hypothèses sur les résidus (test de Durbin-Watson, tests de normalité...)
Mise en garde
Les variables d'une régression ont des mesures parfois très différentes. Un modèle peut intégrer une variable binaire (valeur 0 ou 1) et un PIB exprimé en euros. Par conséquent, il serait risqué de rejeter un coefficient de régression « pifométriquement » proche de zéro ! Voir notamment la page régression avec saisonnalité.
