Dataframes avec pandas (Python)
Plongeons ensemble dans l’univers des dataframes avec Python (on trouve aussi l’orthographe data frame, mais curieusement elle est plus habituelle avec R qu’avec Python ! Voir les data frames avec R).
Imaginez un tableau Excel super puissant, facile à manipuler, rapide et taillé pour faire parler les données : voilà ce qu’est un dataframe. Si vous souhaitez analyser un fichier CSV, nettoyer des données mal fichues ou construire un petit tableau statistique sans vous arracher les cheveux, vous êtes au bon endroit.
Création
D’abord, il faut installer la bibliothèque pandas.
Ensuite, première possibilité, on peut partir d’un dictionnaire.
import pandas as pd
data = {
"Ville": ["Lyon", "Marseille", "Bordeaux", "Caen"],
"Code": [69, 13, 33, 14],
"Département": ["Rhône", "Bouches-du-Rhône", "Gironde", "Calvados"]
}
df = pd.DataFrame(data)
print(df)

Cependant, il est plus courant d’importer un fichier CSV.
import pandas as pd
df = pd.read_csv("data.csv")
À l’inverse, pour exporter de Python en CSV…
df.to_csv("nouveau.csv", index=False)
Exploration
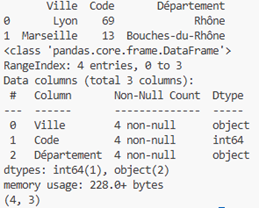
Pour visualiser les premiers éléments (avec notre dataframe df) : df.head()
Pour obtenir des informations sur les données : df.info()
Dimensions (nombre de lignes et de colonnes) : df.shape
Exemple :
import pandas as pd
df = pd.read_csv("data.csv")
print(df.head(2))
df.info()
print(df.shape)
On obtient ceci (copie d’écran VS Code) :
Accès aux données et conditions
Accès à une donnée en particulier, avec ses numéros de ligne et de colonne : df.ilog[n,m]. Par exemple, si l’on souhaite connaître la valeur de la deuxième ligne et de la troisième colonne : print(df.iloc[1,2]) (n’oubliez pas que Python compte à partir de zéro !). On lit Bouches-du-Rhône.
Vous pouvez aussi donner le nom du champ (non pas avec iloc mais avec loc). En l’occurrence, df.loc[1,"Département"] donne le même résultat.
Exemple pour afficher la colonne des départements : print(df["Département"])

Pour afficher les villes et les codes : print(df[["Ville","Code"]])
Pour afficher les trois premières lignes : print(df.iloc[0:3]) (soit trois lignes à partir de la numéro zéro).
Filtrons par exemple les enregistrements dont le code est supérieur à 30 (pour les besoins de l’exemple, ils ont été entrés en numérique) : df[df["Code"]>30]
On peut bien sûr filtrer de façon plus complexe. Si nous souhaitons obtenir les enregistrements dont le code est supérieur à 30 mais sans Bordeaux :
condition = (df["Code"]>30) & (df["Ville"] != "Bordeaux")
print(condition)
Ce script permet d’obtenir :

Modifications
Exemple de modification d’une valeur : df.loc[1,"Ville"] = "Arles"
Exemple de conversion d’une colonne en texte : df["Code"] = df["Code"].astype(str)
Une fois cette conversion réalisée, on peut concaténer cette colonne avec une autre de type texte : df["Lieu"] = df["Ville"] + " (" + df["Code"] + ")"
Ici, nous avons même ajouté deux parenthèses. Notez qu’avec pandas, il existe des façons plus « propres » de concaténer ; mais nous en resterons à cette technique simple.
Suppression d’une ligne : df = df.drop(index = 3)
Suppression d’une ou de plusieurs colonnes : df = df.drop(columns = ["Code","Ville"])
Récapitulons.
import pandas as pd
df = pd.read_csv("data.csv")
df.loc[1,"Ville"] = "Arles"
df["Code"] = df["Code"].astype(str)
df["Lieu"] = df["Ville"] + " (" + df["Code"] + ")"
df = df.drop(index = 3)
df = df.drop(columns = ["Code","Ville"])
print(df)

Renommage de colonne : df = df.rename(columns = {"Lieu":"Commune"})
Tri : df.sort_values(by = "Département", ascending = False)
Ici, l’ordre est décroissant. Quant à l’ordre croissant, il est sélectionné par défaut mais vous pouvez aussi écrire ascending = True.
