Introduction à pandas (Python)
Travailler sur des données avec Python sans pandas, c’est comme faire des calculs avec Excel cellule par cellule. Possible, mais franchement pénible ! La raison d’être de pandas est de rendre les données lisibles, manipulables et d’en tirer de judicieuses informations.
Qu’elles viennent d’un fichier CSV, d’Excel ou d’une base de données, pandas permet de les charger en quelques lignes, de les explorer rapidement et de les transformer très simplement. Trier, filtrer, corriger, regrouper, calculer des statistiques... Tout devient naturel.
Certes, pandas peut sembler un peu dense au début et sa syntaxe demande un petit temps d’adaptation. Mais une fois les bases acquises, c’est un outil redoutablement efficace qui fait gagner du temps et permet de se concentrer sur l’essentiel : comprendre les données et les faire parler.
Installation, lecture et écriture
Sous Anaconda, pandas est généralement déjà installé. Sinon, rendez-vous en page de bibliothèques pour l’installation, l’importation, la lecture et l’écriture des données.
Structures
La Series est un tableau unidimensionnel étiqueté.
s = pd.Series([1, 2, 3, 4])
print(s)
L’index est, par défaut, 0, 1, 2, 3… mais on peut définir un index personnalisé.
s = pd.Series([1, 2, 3], index = [’A’, ’B’, ’C’])
Pour les tableaux bidimensionnels, voir la date sur les dataframes.
Méthodes
Après avoir chargé un jeu de données, la première chose à faire est de les explorer. Les méthodes sont head() pour afficher les premières lignes, tail() pour afficher les dernières, shape pour connaître les dimensions, columns pour afficher les noms des colonnes, tandis que info() fournit des informations sur les types et les valeurs manquantes et describe() afficher des statistiques descriptives.
Les statistiques habituelles sont mean() (moyenne), median() (médiane), min(), max(), sum(), std (écart-type) …
Exemple
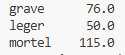
Afin d’explorer davantage les possibilités de pandas, appuyons-nous sur un exemple (fictif). Soit un fichier CSV qui contient des données de sécurité routière.

accidents.csv se présente ainsi :

Premier script (après importation de pandas) :
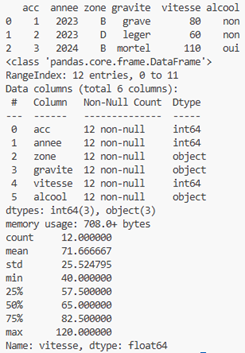
df = pd.read_csv("accidents.csv")
print(df.head(3))
df.info()
print(df["vitesse"].describe())
Nous avons demandé l’affichage des trois premières lignes, puis les informations sur le jeu de données et enfin les statistiques sur la variable numérique vitesse. On obtient ceci (sortie de Visual Studio Code) :
Si l’on ajoute…
print(df["vitesse"].std())
On vérifie l’écart-type qui apparaît dans l’état ci-dessus (avec une floppée de décimales inutiles).
25.524794837866015
Sélection
Réduisons le jeu de données aux seuls accidents avec alcool au volant et vitesse supérieure à 90 et affichons le résultat.
df_risk = df[(df["alcool"] == "oui") & (df["vitesse"] > 90)]
print(df_risk)

Comptage
Nombre d’accidents par gravité…
df["gravite"].value_counts()
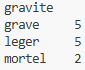
… ou en proportions :
df["gravite"].value_counts(normalize = True)

Pour les statistiques conditionnelles, on utilise groupby. Exemple : vitesse moyenne selon la gravité.
df.groupby("gravite")["vitesse"].mean()
On obtient ceci (bien sûr si l’on a englobé la ligne ci-dessus dans un print) :