Web et moteurs de recherche
Pour beaucoup, la toile d’araignée mondiale (World Wide Web) a rapidement pris une place centrale, tant dans la vie privée que professionnelle. Grâce à cet outil, nous vivons à l’ère de l’information (mais aussi de la désinformation !) et il n’est plus nécessaire de se déplacer pour effectuer ses achats ou ses démarches administratives. Arrêtons-nous là, il serait vain de vouloir énumérer toutes les modifications de comportement dues au web.
Pour autant, le connaissons-nous bien ? Certes, de même qu’il n’est pas nécessaire de connaître le principe du moteur à explosion pour conduire une voiture, il n’est pas indispensable de savoir comment fonctionne le protocole http pour surfer sur le web ! Cependant, il serait dommage de ne pas profiter des connaissances que le web, en particulier cette page, peut vous offrir…

Naissance
Les grands inventeurs et découvreurs du passé sont souvent bien connus du grand public : Edison, les frères Lumière, Pasteur… Curieusement, les contemporains qui ont changé notre vie le sont beaucoup moins. Tim Berners-lee est de ceux-ci.
Cet informaticien anglais proposa en 1989 d’associer le principe des liens hypertextes, inventés par Ted Nelson en 1965, à Internet. Au départ, le but n’était que faciliter les échanges au sein du CERN (Conseil Européen pour la Recherche Nucléaire). Ce fut rapidement réalisé… puis étendu au monde entier.
Le web n’est donc pas né aux États-Unis comme la plupart des gens le croient mais en Suisse.
Aujourd’hui, Tim Berners-Lee dirige l’organisme de standardisation qu’il a créé, le W3C (World Wide Web Consortium).
Protocole
Le protocole de communication du web a été défini dès 1990. Il s’agit du fameux http qui apparaît lorsqu’une page s’affiche (HyperText Transfert Protocol) ainsi que du https dans sa variante sécurisée (association du http avec le protocole de sécurisation SSL).
Ce protocole permet le transfert de fichiers entre clients (navigateurs) et serveurs.
Architecture client-serveur
Il faut bien distinguer le web des autres utilisations d’Internet (courrier électronique, pair à pair, transfert de fichiers, streaming...).
Un serveur web abrite les ressources (pages web, images…) ou les récupère sur des hôtes distants. Il utilise un serveur HTTP (Apache, Nginx…) pour répondre aux requêtes des clients par Internet (ou par un intranet).
Le client HTTP est un logiciel qui permet de se connecter à un serveur. C’est généralement un navigateur.
Le navigateur (Chrome, Firefox, Safari, Opera, Edge…) envoie au serveur une requête HTTP qui comprend notamment l’URL (voir ci-dessous). Celui-ci retourne une réponse HTTP, dans laquelle se trouve la page demandée, quel que soit le système d’exploitation ou le type de matériel (smartphone, ordinateur de bureau…).
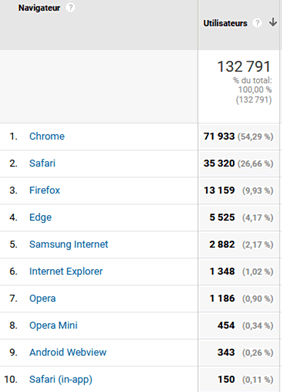
Pour un site francophone comme celui que vous êtes en train de consulter, plus de la moitié des utilisateurs utilisent Chrome. L’extrait de Google Analytics ci-dessous montre quels navigateurs ont permis de consulter ce site au cours du mois d’avril 2020.
Comme nous l’avons vu, ce sont les liens hypertextes qui définissent le web. Ils peuvent être internes au site (par exemple ceux qui figurent dans le texte de cette page) ou renvoyer à une ressource externe.
Il est ainsi possible de naviguer sur des milliards de sites en passant des uns aux autres par des liens. Mathématiquement, le web s’apparente à un gigantesque graphe orienté (les arcs étant les liens).
L’URL
On identifie une page web par une adresse : son URL (Uniform Resource Locator).
Elle comprend le nom du protocole (par exemple http://) puis celui du domaine (par exemple wwww.jybaudot.fr) puis l’arborescence des dossiers permettant de localiser la page. Ainsi, celle que vous avez sous les yeux se nomme web.html et se trouve dans le dossier Internet. C’est pourquoi vous lisez dans votre navigateur au-dessus de cette page www.jybaudot.fr/Internet/web.html.
Pour accéder à une page sécurisée, vous devez aussi entrer un identifiant et un mot de passe.
Sites particuliers
Un wiki est un site doté d’une application particulière permettant une mise à jour collaborative. Le plus utilisé est l’encyclopédie universelle Wikipédia, créée en 2001.
Un blog est un site qui a pour objet la diffusion d’articles sur un thème particulier, du plus récent au plus ancien. Il permet à chacun de s’exprimer sur son sujet de prédilection (cuisine, politique, critique littéraire…).
Moteur de recherche
Un utilisateur peut saisir directement une URL. Mais bien souvent, il entre un ou plusieurs mots-clés dans un moteur de recherche qui lui retourne un certain nombre de pages web susceptibles de répondre au mieux à la demande.
Il en existe un large choix. Cependant, le plus célèbre est celui de Google, suivi loin derrière par Bing. Au début des années 2000, le plus utilisé était celui de Yahoo!. Mentionnons aussi le français Qwant. Google donne aussi la possibilité de créer un moteur de recherche soi-même parmi un nombre limité de sites.
Ces outils s’appuient sur des techniques qui sont les secrets les mieux gardés du web et qui évoluent sans cesse. Lorsqu’un utilisateur saisit un mot-clé sur Google, la première page proposée a de bien meilleures chances d’être lue, puis la deuxième et ainsi de suite. Pour un site marchand, c’est l’assurance de meilleures ventes. L’enjeu économique est donc crucial pour une entreprise de commerce en ligne.
D’où l’émergence d’une profession : référenceur. Son but est d’améliorer la visibilité d’un site sur le web. En effet, bien que les règles soient inconnues et très complexes, il existe quelques astuces pour améliorer l’indexation. Il reste que le métier de référenceur est assez technique, entre le marketing et l’informatique.
Comment fonctionne un moteur de recherche ? Des robots, appelés spiders, parcourent le web et indexent pour des millions de mots les milliards de pages web qui s’y rapportent avec les liens qui s’y trouvent. Les cheminements des internautes entre les sites sont eux aussi mémorisés. Ensuite, les pages sélectionnées sont triées en fonction de nombreux critères par des programmes qui s’appuient sur l’intelligence artificielle. Citons-en quelques-uns : le nombre de visites, les mots-clés, l’ergonomie, l’architecture du site, l’absence de liens morts (erreur 404), la vitesse de chargement, la notoriété sur les réseaux sociaux… La prise en compte de ces nombreux critères permet au moteur de recherche de classer les URL détectées en les classant par ordre décroissant de pertinence (supposée) pour l’internaute.
