Typologies
Comment, grâce à des échelles d’attitude, distinguer les bons, les brutes et les truands ? Comment, à partir d’une base de données, partitionner la clientèle d’une banque pour contacter les cibles d’un nouveau produit financier ? Grâce à une classification ! Sur cette page est présentée la technique de classification non hiérarchique la plus utilisée. Les k-means permettent de partitionner une population décrite par des variables, le plus souvent quantitatives.
Certains auteurs nomment cette technique « centres mobiles » et réservent le terme k-means à la version incrémentale (évoquée plus bas). Nous avons opté pour la terminologie « k-means » car elle est davantage employée en entreprise.
Comment procéder ?
Préalablement, rappelons qu’une typologie permet d'organiser des variables quantitatives. Si les individus ou unités statistiques sont décrits par des variables qualitatives (code PCS, sexe, titulaire ou non d’un plan d’épargne…), ces dernières doivent être codées de façon disjonctive puis faire l’objet d’une ACM. On utilise alors les coordonnées des individus sur les axes factoriels. Ce sont des variables certes abstraites mais tout de même quantitatives.
En premier lieu, et c’est hélas une des limites de cette méthode, on CHOISIT un nombre \(k\) de classes à obtenir. Si la configuration de la population ou de l'échantillon se prête parfaitement à un autre nombre de clusters, c’est dommage ! C’est pourquoi les k-means sont souvent précédées d’une ACP (variables quantitatives) ou d’une ACM (variables qualitatives) qui permettent de visualiser la structure d’une population et, parfois, de faire apparaître des nuages plus ou moins formés. Des logiciels savent enchaîner les deux traitements dans une même procédure. Une autre solution consiste à réaliser d’abord une CAH.
Deuxièmement, vous ou votre logiciel choisissez \(k\) individus, au hasard ou non. Là aussi, grosse limite : si vous tombez sur un outlier, les conclusions de l’analyse risquent d’être faussées car le résultat final dépend du choix initial. D’où un deuxième avantage à commencer par une analyse factorielle qui permet de détecter ces drôles d’individus afin de les écarter. En tout état de cause, il est fortement recommandé de procéder à plusieurs classifications puis de retenir celle qui semble la « meilleure » (\(R^2\), homogénéité des clusters, bon sens…).
Les valeurs sont centrées et réduites par le logiciel (sauf si cette étape est proposée dans les options).
La classification s’effectue ensuite selon un processus itératif. D’abord le logiciel mesure la distance de chaque observation avec les \(k\) points initialement choisis pour le « relier » à l’un d’entre eux. Le nuage est maintenant découpé en \(k\) zones convexes de points, dont les barycentres sont calculés, puis le logiciel mesure à nouveau les distances de chaque point mais cette fois par rapport à ces barycentres. Certains points changent donc de classe. Qui dit réaffectations dit nouveaux barycentres, et ainsi de suite. Le logiciel arrête de tourner lorsque tout ce joli monde s’est bien fixé, à moins que vous ne l’ayez paramétré pour qu’il exécute un nombre fixé d’itérations.
Voici pour le principe. Mais comment mesurer ces fameuses distances ?
Il existe un choix de plusieurs métriques. En général on utilise les carrés des distances euclidiennes, c’est-à-dire la matrice d’inertie. Donc, on minimise la somme des variances intra-classe (variance = inertie si toutes les pondérations sont égales). XLSTAT vous permet aussi de choisir le déterminant de cette matrice, qui supporte mieux les effets d’échelle entre variables mais qui risque davantage de trouver des classes de tailles hétérogènes (dixit le manuel du logiciel). Cela dit, les petites classes sont souvent très instructives.
Critères de qualité
Malheureusement, il n’existe pas de mesure fiable et pratique pour juger la qualité d’une typologie. Le \(R^2\) se calcule facilement : \(\frac{\scr{inertie\;interclasse}}{\scr{inertie\; totale}}.\) Mais il augmente avec le nombre de clusters, tout comme il augmente avec le nombre de variables dans une régression multiple, et la classification perd en robustesse. On ne peut pas procéder à une ANOVA dans la mesure où les hypothèses nécessaires à cette technique n’ont aucune raison d’être vérifiées. Alors que faire ?
D’abord, si le test du F n’est pas valide, la statistique du F peut toujours être utilisée de façon « dégradée » pour vérifier si les clusters présentent des dispersions homogènes.
Globalement, on peut déterminer un pseudo F de Fisher qui ne suit pas une loi de Fisher et qui doit être le plus élevé possible. Comme d’habitude, \(n\) est le nombre d’observations et \(k\) est le nombre de classes.
\[\mathscr{pseudo}\;F=\frac{\frac{R^2}{k-1}}{\frac{1-R^2}{n-k}}\]
Une autre solution consiste à procéder à une analyse factorielle discriminante.
Variantes
Le K-means incrémental : les observations sont ajoutées les unes après les autres et le logiciel recalcule les barycentres après chaque ajout. L’algorithme est plus rapide.
Les nuées dynamiques : on n’initialise pas le traitement avec des observations mais avec des ensembles d’observations représentatives.
Exemple synthétique
Dans le cadre d’une étude de marché, le directeur des ventes d’un hebdomadaire compare la part de marché de ce dernier et de cinq de ses concurrents dans le département de l’Ain. Il dispose du tableau suivant, qui indique pour un certain nombre de points de vente la part de marché de chacun des six hebdomadaires (à l’exclusion d’autres éventuels concurrents) et souhaite retenir trois classes :
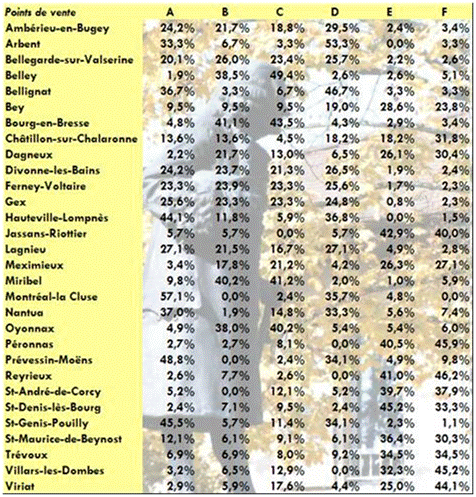
Les logiciels vous offrent plus ou moins d’informations. La typologie a été réalisée avec Tanagra (Clustering puis K-Means) et XLSTAT (Nuées dynamiques k-means), d’où est extrait le tableau suivant. Les affectations aux classes ont été les mêmes avec les deux logiciels.
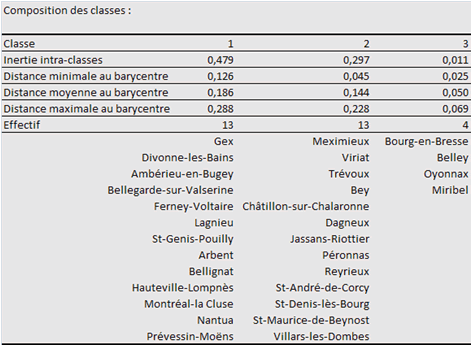
Les résultats sont d’autant plus tranchés que l’exemple était fictif… Les points de ventes situés dans des zones montagneuses sont en classe 1, la classe 2 regroupe l’ouest du département et la classe 3 comprend les villes les plus peuplées (plaine ou montagne).
