Loi de Weibull : rangs médians et MV sur Weibull++
Cette page est un complément à la page loi de Weibull à 2 paramètres, qui vous a certainement donné envie d’en savoir davantage… Son objet est de montrer plusieurs façons de déterminer ces fameux paramètres.
Données de l'exemple
Prenons ce même exemple de dix tondeuses pour chiens qui tombaient en panne après un nombre variable de tontes. Nous vous rappellons ces données tout en priant les constructeurs de tondeuses d’accepter nos excuses si ces chiffres s’éloignent sensiblement d’une réalité que nous ignorons (n’étant pas du métier !).

Aucune donnée n’est « censurée », c’est-à-dire que l’on a attendu la défaillance pour chacune d’elles.
Représentation graphique
En page de loi de Weibull, cet exemple est traité par Statgraphics Centurion, les paramètres de la loi étant estimés par la méthode du maximum de vraisemblance. Le graphique de Weibull, dont la graduation particulière du repère permet de comparer la fonction de répartition ainsi transformée à une droite, apparaît ainsi, cette fois-ci sur le progiciel Weibull++ :
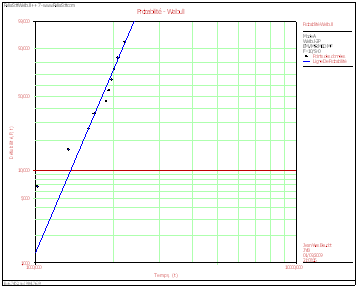
Les paramètres sont (heureusement) les mêmes qu’avec Statgraphics, c’est-à-dire 6,7452 pour le paramètre de forme (shape parameter nommé Beta par Weibull++) et 1904,76 pour le paramètre d’échelle (scale parameter), baptisé ici Eta.
Les avantages d’un diagramme à repère fonctionnel sont de juger rapidement si la loi de Weibull avec les deux paramètres déterminés par le logiciel sont corrects et éventuellement d’en introduire un troisième (location parameter), que l’on n’étudiera pas ici.
Technique
Si cette présentation rappelle la bonne vieille régression linéaire simple, ce n’est toutefois pas cette technique qui est utilisée pour concurrencer celle du maximum de vraisemblance.
En effet, c’est la régression sur les rangs qui apparaît comme l’alternative la plus courante. Sur Weibull++, cette régression est réalisable sur les \(X\) ou sur les \(Y.\) L’un des avantages de la régression est d’être gratifié d’un coefficient de corrélation des rangs, indicateur de la qualité du modèle.
Le graphique ci-dessous est celui d’une régression sur les rangs des \(X\) et ô surprise, le nuage de points n’est pas résumé de la même façon. La pente est beaucoup moins raide. Le paramètre de forme s’élève à 4,8846 et celui d’échelle flirte avec les 1926. Pourtant, il est visuellement difficile de sélectionner une droite plutôt qu’une autre. Les deux semblent correctes.
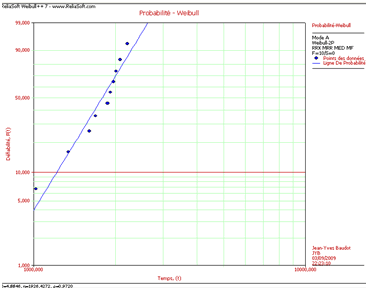
Une régression sur les rangs des \(Y\) nous donne un paramètre de forme de 4,6146 et un paramètre d’échelle d’environ 1939. Le coefficient de corrélation reste sur ses positions, à savoir 0,972.
Pour les puristes, précisons que la méthode de rang est celle des rangs médians ; celle de Kaplan-Meier donne des résultats moins bons (\(ρ = 0,943).\)
Le rang médian est estimé par la formule \(\frac{n_i - 0,3}{N + 0,4},\) \(n_i\) étant le nombre cumulé d’appareils défaillants à l’instant \(t.\) \(N\) représente la taille de l’échantillon.
Dans notre exemple, il est très facile de déterminer avec un tableur les rangs médians : (0,3 ôté de la cellule à gauche, le tout divisé par 10,4). Cependant, cette formule simple est une approximation et votre logiciel peut montrer « quelques points de divergence » (comme on dit en politique).
Les rangs ainsi obtenus sont les ordonnées des points du nuage.
Pour davantage de précisions (en anglais) :
http://www.weibull.com/lifedatawebcontents.htm
