Fonctions de répartition discrètes, continues et empiriques
La fonction de répartition (distribution function) est une notion clé de la théorie des probabilités. Elle indique, pour la valeur donnée prise par une variable aléatoire (v.a), un cumul de probabilités.
Discrète ou continue
Soit une fonction \(F\) associée à une v.a \(X.\) \(F\) est une fonction de répartition si \(F(x) = P(X \leqslant x).\)
Elle est croissante sur \(\mathbb{R}\) et varie de 0 à 1, autrement dit :
\(\mathop {\lim }\limits_{x \to - \infty } F(x) = 0\) et \(\mathop {\lim }\limits_{x \to + \infty } F(x) = 1\)
Si la v.a est discrète, il s’agit d’une fonction en escaliers. Soit \(p_i\) la probabilité que \(X\) prenne la valeur \(x_i.\)
Appliquons la propriété des probabilités totales :
\(\displaystyle{F(x) = \sum_{x_i \leqslant x}p_i}\)
Cette somme est finie si l’ensemble de définition est fini et infinie si cet ensemble est infini dénombrable (loi de Poisson, par exemple).
Ci-dessous figure la représentation graphique d'une fonction de répartition associée à un lancer de dé non truqué.
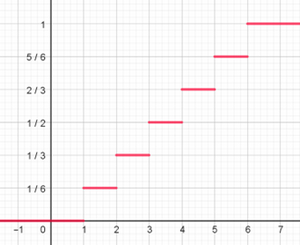
Si la v.a est continue :
\(\displaystyle{F(x) = \int_{- \infty}^{x} f(t)dt}\)
Dès lors, vous comprenez pourquoi la fonction de répartition s’écrit généralement avec un F majuscule (c'est une primitive de la fonction de densité).
L’un de ses intérêts les plus immédiats est de donner immédiatement la probabilité \(P(X \leqslant x)\) mais aussi, pour \(a\) et \(b\) réels avec \(a < b,\) \(P(a < X \leqslant b).\) En effet, il est évident que \(P(a < X \leqslant b)\) \(=\) \(F(b) - F(a).\)
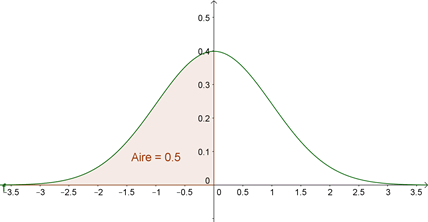
Pour visualiser le lien entre les fonctions de densité et de répartition, prenons l’exemple très simple de la loi normale centrée réduite. La probabilité pour qu’une valeur de \(x\) soit inférieure à 0 s'établit à 0,5.
Si l’on illustre ceci avec la courbe représentative de la fonction de densité, nous obtenons ceci (avec Geogebra) :
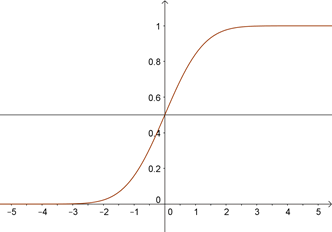
Quant à la courbe représentant la fonction de répartition, elle contient le point de coordonnées \((0\,; 0,5)\) :
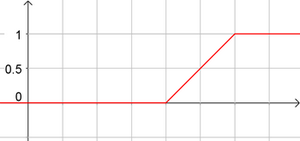
La représentation la plus simple est celle de la fonction de répartition d’une loi uniforme :
Fonction de répartition empirique
Soit un échantillon dont l'effectif est \(n.\) Les observations sont triées par valeurs croissantes de \(x_i,\) valeurs prises par une v.a \(X.\)
La fonction de répartition empirique \(F_n\) est une fonction en escaliers. Elle est définie ainsi :
Si \(x < x_1,\) alors \(F_n(x) = 0\)
Si \(x \geqslant x_n,\) alors \(F(x) = 1\)
\(F\) est constante sur l'intervalle \([x_i \, ; x_{i+1}[.\)
Chaque marche a une hauteur de \(\frac{1}{n}.\)
En général, cette fonction n’a pas d’expression algébrique mais sa représentation graphique est très simple à tracer.
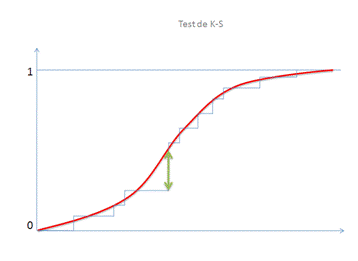
On démontre que \(F_n(x)\) converge presque sûrement vers la fonction de répartition réelle \(F(x).\)
On démontre aussi que la v.a que constitue l’écart maximal entre \(F_n(x)\) et \(F(x)\) tend vers 0 (convergence presque uniforme). C’est le théorème de Glivenko-Cantelli dit encore théorème fondamental de la statistique puisqu’il justifie de façon mathématique l’emploi d’échantillons pour représenter les populations. La notation de cette v.a n’est pas fixée : \(D,\) \(D_n,\) \(X_n…\) C’est la statistique de Kolmogorov.
Le test de Kolmogorov-Smirnov se fonde sur sa loi de probabilité.
Note : on utilise des fonctions de répartition multivariées pour des couples et des n-uples de v.a.
